Projekt CASPAR a uchovávání digitálních informací
Na realizaci projektu CASPAR se podílejí a na přípravě tohoto textu spolupracovali také Luigi Fusco (ESA/ESRIN), Seamus Ross, (HATII, University of Glasgow), Mariella Guercio (University of Urbino), Mario Hernandez (UNESCO), Ugo Di Giammatteo (ACS), Zavisa Bjelogrlic (ASemantics), Dalit Naor (IBM/Haifa), Carlo Meghini (CNR), Silvia Boi (MetaWare), Daniel Terrgui (INA), Kia Ng (University of Leeds), Luigi Briguglio (Engineering), Vassilis Christophides (FORTH), Bruno Bachimont (CNRS/UTC), Hugues Vinet (IRCAM) a Pavel Sedlák (CIANT).
V anglické verzi byl článek již publikován, a to v International Journal of Digital Curation (2007, vol. 2, issue 1). Článek byl publikován pod názvem pod názvem The CASPAR Approach to Digital Preservation a je dostupný na adrese http://www.ijdc.net/ijdc/article/view/29/32.
Z anglického originálu do češtiny přeložili Eduard Piňos a Michal Máša (CIANT).
V pondělí 29. 10. 2007 se od 19:30 v Galerii CIANT (Křížkovského 18, 130 00, Praha 3, http://www.ciant.cz/gallery/) uskuteční přednáška autora tohoto článku D. Giaretty týkající se projektu CASPAR. Přednáška proběhne v angličtině a je přístupná široké veřejnosti.
Dr. David Giaretta je zástupcem ředitele vývoje Střediska pro správu digitálních informací (UK DCC) a nyní i ředitelem projektu CASPAR. Je jedním ze spoluautorů referenčního modelu OAIS (Open Archival Information System, Otevřený archivační informační systém), ze kterého projekt CASPAR vychází. D. Giaretta se zabýval se astronomickým výzkumem, konkrétně využitím dat z astronomických satelitů, řídil mnoho archivačních a softwarových projektů. Jeho současným pracovištěm je Rutherford Appleton Laboratory ve Spojeném království.
Úvod
Dlouhodobé uchovávání digitálních informací je složitý problém, což potvrzuje řada studií a článků. Důležitým standardem v této oblasti je referenční model OAIS [1]. I když tento model pojímá uchovávání digitálních informací velmi obecně, z tohoto pojetí ve skutečnosti plyne, že problém je ještě složitější, než by se mohlo zdát.
Obecně vzato, uchování digitálního objektu vyžaduje dlouhodobé nepřetržité úsilí. Můžeme namítnout, že je možné vytvořit digitální objekt vytesáním jedniček a nul do kamene, což se osvědčilo jako velice odolná metoda uchovávání informací, jak ostatně věděli již staří Egypťané. Avšak, jak vysvětlíme později, i když tato metoda může umožnit přístup k informaci (i když pomalý), nezajistí její srozumitelnost.
Nepřetržité úsilí vyžaduje nepřetržité financování. Je však nutné si přiznat, že žádná organizace, projekt ani osoba nemohou zaručit, že jejich financování bude trvat věčně (či třeba jen příštích pět až sedm let). Domníváme se, že pokud žádný subjekt nemůže zaručit financování, snahu (nebo dokonce ani zájem), je nutné tyto náklady na uchovávání nějak sdílet. To však představuje mnohem více než jen jednoduchý řetězec, ve kterém se předávají soubory bitů z jednoho držitele na druhého. K předávání bitů samozřejmě dojít musí, třeba vytvářením duplicitních kopií (podobně jako kopií knih), v digitálním světě můžeme uvést například LOCKSS [2]. Abychom však učinili informaci srozumitelnou, ne pouze přístupnou, potřebujeme něco navíc.
CASPAR (Cultural, Artistic and Scientific knowledge for Preservation, Access and Retrieval) je integrovaný projekt Evropské unie, který započal v dubnu 2006, má celkovou finanční podporu ve výši 16 mil. euro (z toho 8,8 mil. euro z EU) a zaměřuje se přímo na tento problém. V tomto článku popisujeme některé ze základních konceptů projektu CASPAR a měřítka, podle kterých by měl být CASPAR posuzován společně s jinými projekty zaměřenými na uchovávání digitálních informací.
V rámci projektu CASPAR bylo vytvořeno konsorcium zahrnující významné digitální fondy s odpovídající vědeckou (CCLRC [hlavní partner] a ESA), kulturní (UNESCO) a kreativní expertízou (INA, CNRS, University of Leeds, IRCAM a CIANT), dále komerční partnery (ACS, ASemantics, MetaWare, Engineering, a IBM/Haifa), experty v oblasti znalostního inženýrství (CNR a FORTH) a partnery z akademické sféry (University of Glasgow a University of Urbino).
Hlavními cíli projektu CASPAR jsou:
- vytvoření základních komponent infrastruktury umožňující uchovávání digitálních informací (v souladu s referenčním modelem OAIS);
- validace této infrastruktury, tj. zjištění, zda může projekt poskytnout důkazy o tom, že nástroje a technologie prohlášené za účinné pro uchovávání digitálních informací jsou skutečně účinné.
Řešení nebo nafouknutá bublina?
Je jednoduché navrhovat řešení, která však postrádají jiný důkaz o účinnosti než prosté dlouhé čekání. To nás v jistém smyslu přivádí ke zkratce CASPAR. Důvod, proč jsou v ní obsažena slova věda, umění a kultura, je ten, že chceme ověřit to, co děláme, a ověřit to „reálně“ v rozmanitých scénářích zahrnujících vědecká data z ESA a CCLRC, informace o kulturním dědictví z UNESCO a umělecká díla v rámci IRCAM, University of Leeds, INA a CIANT.
Je například velmi jednoduché prohlásit, že řešením je převést vše do XML. Je to však možné ověřit? Je možné tvrdit a na konkrétním příkladě ukázat, že určitá technika, například emulace, funguje. Funguje ale pro všechny typy digitálních informací? Co vlastně znamená tvrzení: „Uchovávám tento digitální objekt“?
Model OAIS vyžaduje existenci způsobu ověření tohoto tvrzení, přičemž kritériem je, že informace se musí uchovat tak, aby byla srozumitelná a použitelná. To nás přivádí k jednomu z konceptů v modelu OAIS označovanému jako reprezentační informace (Representation Information). OAIS definuje reprezentační informaci jako informaci, která mapuje datový objekt (Data Object) do smysluplnější formy. Je to shrnující koncept, který v zásadě pokrývá vše, co je potřeba k učinění určitého souboru bitů (Content Data Object) srozumitelným a použitelným. Není však možné suše konstatovat, že potřebujeme reprezentační informaci. V modelu OAIS je reprezentační informace zároveň datovým objektem, který potřebuje svoji vlastní reprezentační informaci. Síť reprezentací (Representation Network), kterou OAIS definuje jako množinu reprezentačních informací, jež plně popisuje význam datového objektu, může být velmi rozsáhlá, jak je naznačeno v následujícím příkladu reprezentační informace pro Marťany:
Reprezentační informace pro Marťany
Kolik reprezentační informace by bylo třeba, aby mohl Marťan pochopit a použít digitálně kódovaná data z ionosondy (viz http://en.wikipedia.org/wiki/Ionosonde)?
Kde začít? Třeba s definicí papíru a formátu a možná ekvivalentem Rossetské desky pro marťančinu a angličtinu (nebo čínštinu či jakýkoliv jiný jazyk, ve kterém je dokument napsán). Ale co ostatní věci, jako například bity, binární zápis, kódování IEEE pro čísla s pohyblivou řádovou čárkou, definice jmen datových hodnot, vztahy mezi datovými hodnotami, definice frekvence, definice sekundy, základní fyzika, pokročilá fyzika, angličtina…atd.? Jejich seznam je velmi dlouhý.
Aby bylo možné nějakým způsobem rozsah sítě reprezentací omezit, přichází model OAIS s konceptem předem určené komunity (Designated Community). Jedná se o definovanou skupinu potenciálních uživatelů, kteří by měli být schopni porozumět konkrétnímu souboru informací. To však zadrží záplavu reprezentačních informací jen dočasně. Problém spočívá v tom, že to, co představuje znalosti předem určené komunity, tedy tzv. znalostní bázi (Knowledge Base), a co jí nemusí být poskytnuto jako reprezentační informace, se s časem mění. Jinými slovy, i kdybychom mohli vytesat binární kód do kamene nebo něčeho podobně odolného, jednalo by se pouze o částečné řešení – zajistili bychom přetrvávající přístup, ale ne přetrvávající srozumitelnost.
Měřítka pro validaci
Projekt CASPAR předkládá [3] několik obecných měřítek pro svou vlastní validaci. Tato měřítka by s drobnými úpravami měla být použitelná také pro většinu dalších technik uchovávání digitálních informací. Těmito měřítky jsou:
- demonstrace dostatečného teoretického základu pro zvolený přístup;
- praktická demonstrace pomocí tzv. testů zkrácené životnosti zahrnující:
- změny prostředí (včetně změn softwaru a hardwaru);
- změny v předem určené komunitě a její znalostní bázi;
- demonstrace zvýšené důvěryhodnosti datových úložišť.
Je třeba zmínit, že výše uvedené nám nemůže poskytnout absolutní důkaz, ale pouze podpůrné důkazy pro tvrzení o účinnosti.
Sdílení nákladů
Vrátíme-li se k problematice sdílení nákladů na uchovávání digitálních informací, můžeme zde spatřovat jistou analogii s Wikipedií, která disponuje obrovským množstvím přispěvatelů, jež vytvářejí, opravují či komentují její obsah, a která se stala nejrelevantnějším (nebo alespoň nejvyhledávanějším) zdrojem informací na internetu. Podobná snaha o zapojení mnoha přispěvatelů probíhá v BBC, která se snaží o vytvoření jakéhosi „wikirádia“ [4], které umožňuje veřejnosti komentovat nahrané dokumenty. Dalším příkladem je vyhledávač Google, jenž nezávisí na vlastním hodnocení významu stránky, nýbrž na tom, jak danou stránku hodnotí jiní. Knihy, mezi něž patří např. Moudrost davu (The wisdom of crowds), nabízejí mnoho obdobných příkladů využití této moudrosti.
Uchovávání digitálních informací však musí být víc než pouhá obdoba Wikipedie. Je třeba jednat aktivně, aby informace nebyly zapomenuty a ztraceny. Právě k tomu jsou určeny komponenty infrastruktury vytvářené v rámci projektu CASPAR.
Infrastruktura pro uchovávání digitálních informací
Obr. č. 1 zobrazuje prototyp architektury, která je detailně popsána v dokumentu CASPAR Conceptual Model [5]. Klíčovou komponentou infrastruktury pro uchovávání digitálních informací je registr/úložiště (Registry/Repository). Mezi jeho funkce patří ukládání, nacházení a sdílení reprezentačních informací. Za zmínku stojí, že značná část počátečního vývoje [6] registru/úložiště byla uskutečněna ve Středisku pro správu digitálních informací (Digital Curation Center, DCC) [7].
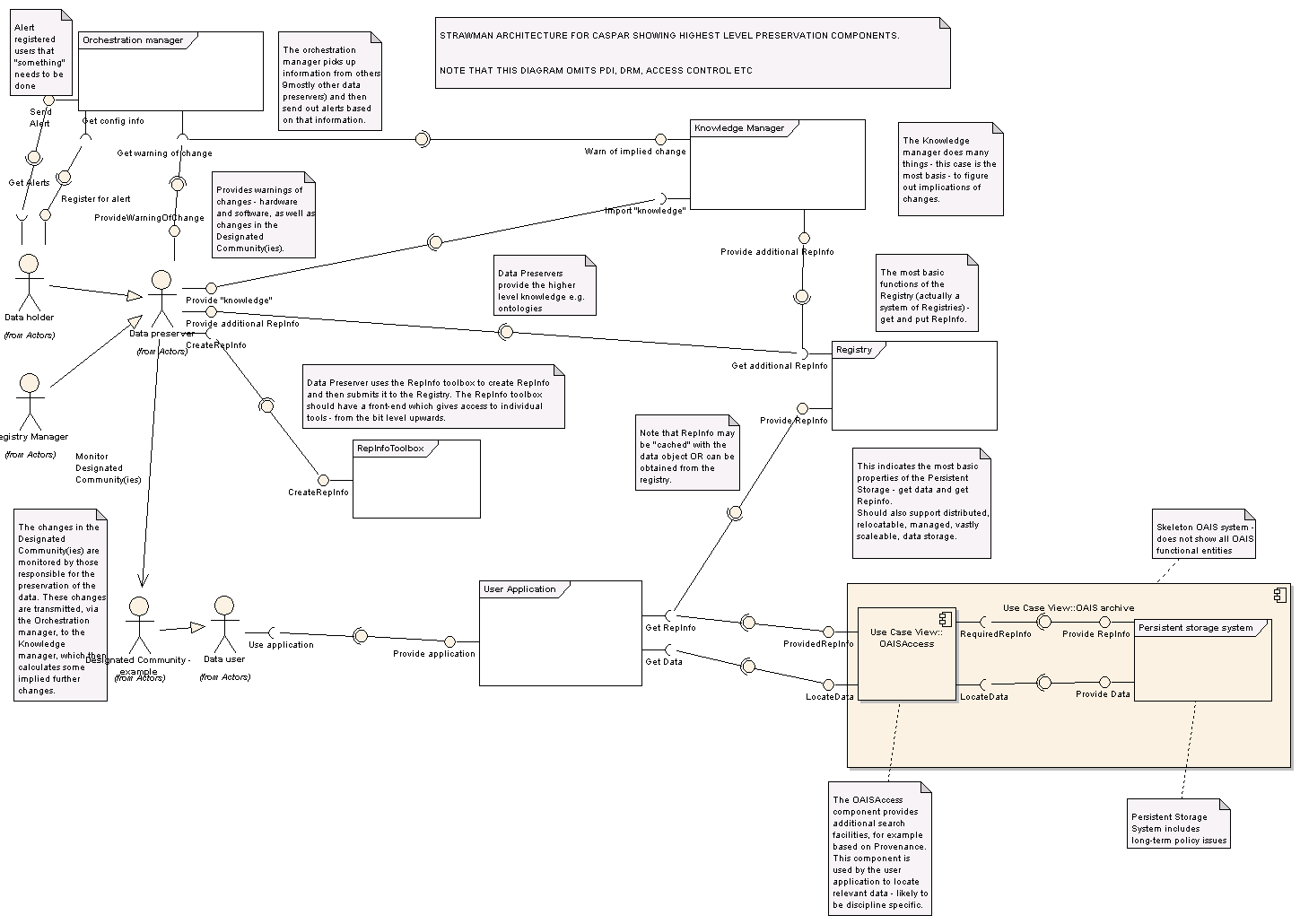
Obr. č. 1: Klíčové komponenty infrastruktury vytvářené v rámci projektu CASPAR
Identifikátory (Curation Persistent Identifiers, CPID) jsou svázány s libovolným datovým objektem a odkazují na příslušnou reprezentační informaci v registru/úložišti (viz Obr. č. 2). Samotná reprezentační informace vrácená registrem/úložištěm je také digitálním objektem s vlastním identifikátorem.
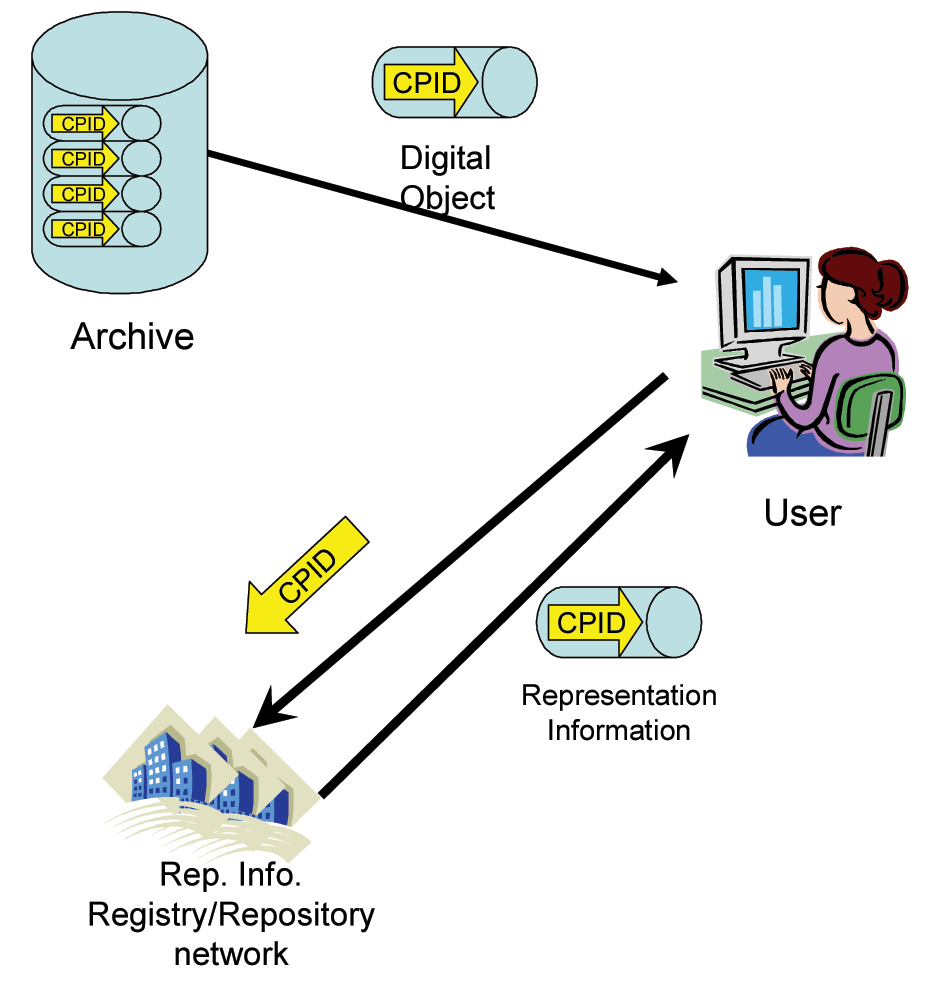
Obr. č. 2: Použití registru/úložiště reprezentační informace
Výše uvedené však neznamená, že by musel existovat jediný unikátní registr/úložiště, nebo dokonce jediná definitivní reprezentační informace pro každou digitální informaci.
Registr/úložiště doplňuje komponenta znalostního správce (Knowledge Manager), který identifikuje mezery v reprezentační informaci – ty je pak nutné doplnit. Informace mají samozřejmě svůj zdroj. Jsou jím nejprve lidé, ti poskytují informace organizačnímu správci (Orchestration Manager), který je shromažďuje a distribuuje.
Podporu pro automatickou identifikaci těchto mezer, založenou na obdržených informacích, ukazuje obr. č. 3. Ten znázorňuje uživatele (u1, u2…) s uživatelskými profily (p1, p2… popisují uživatelovu znalostní bázi) a reprezentační informaci (m1, m2…) k porozumění digitálním objektům (o1, o2…).
Vezměme si například uživatele u1, který se snaží porozumět digitálnímu objektu o1. K tomu, aby porozuměl objektu o1, potřebuje reprezentační informaci m1. Profil p1 ukazuje, že uživatel u1 rozumí m1 (a tedy i m2, m3 a m4 na m1 závisejících), a tak má dostatek reprezentačních informací, aby porozuměl objektu o1.
Pokud se uživatel u2 snaží porozumět objektu o2, je zřejmé, že objekt o2 potřebuje reprezentační informaci m3 a m4. Profil p2 ukazuje, že uživatel u2 rozumí reprezentační informaci m2 (a tedy i m3). Zde je však mezera, konkrétně se jedná o reprezentační informaci m4, bez které uživatel u2 nemůže porozumět objektu o2.
Aby uživatel u2 porozuměl objektu o1, je třeba mu poskytnout reprezentační informaci m1 a m4.
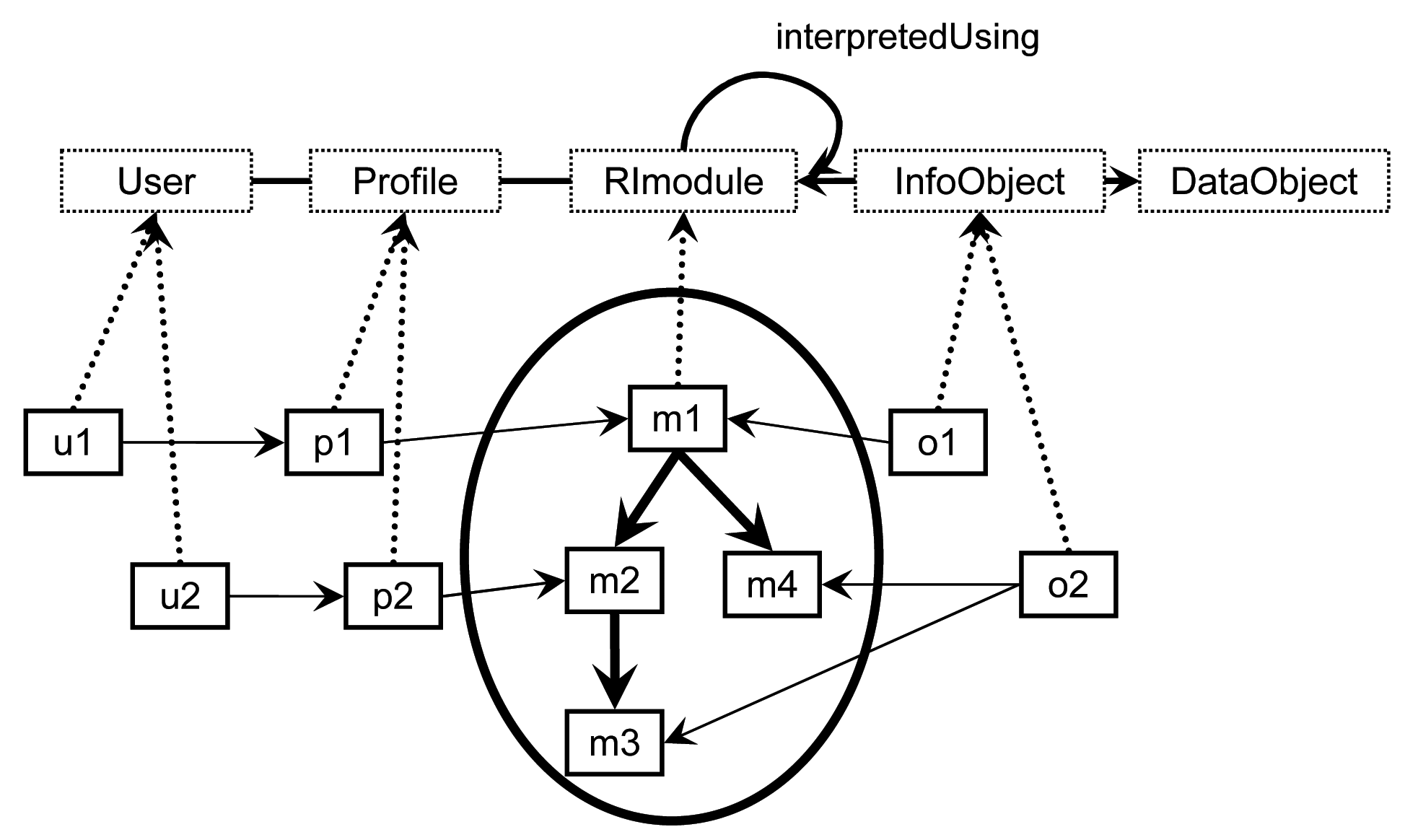
Obrázek č. 3: Modelování uživatelů, profilů, modulů a závislostí
Výše uvedené ilustruje jednu z oblastí v rámci projektu CASPAR, která využívá řízení znalostí (Knowledege Management). Jeho další použití se týká shromažďování sémantické reprezentační informace (Semantic Representation Information). S formální podobou výše uvedených úvah je možné se seznámit v [8] a [9].
Automatizace a poměr cena/výkon
Zcela přijatelnou formou reprezentační informace by jednoduše mohl být (pravděpodobně velmi rozsáhlý) papírový dokument, v němž by byly popsány všechny aspekty získávání smysluplné informace z binárních sekvencí. Pokud by takový dokument byl jedinou dostupnou reprezentační informací, pak je to samozřejmě lepší než nemít k dispozici žádnou reprezentační informaci.
Avšak hlavní nevýhoda takovéto formy reprezentační informace spočívá v tom, že je složité ji používat, neboť je pro ní (nyní) potřeba člověk, aby ji přečetl a porozuměl jí. V případě, že máme co dočinění se stovkami či tisíci různých typů datových objektů, jedná se zcela jistě o relativně pomalé, nákladné a složité řešení.
Projekt CASPAR se tam, kde je to možné, zaměřuje na vytváření takových typů reprezentační informace, které podporují automatizaci a které by se tak daly pravděpodobně použít i v budoucích nástrojích a softwarech.
Warwickský workshop [10] ukázal, že klíčem je virtualizace s využitím vrstevnatého modelu (viz obr. č. 4).
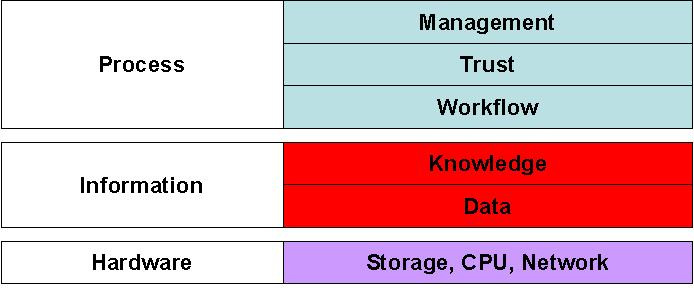
Obr. č. 4: Virtualizační vrstvy
Avšak ani virtualizace není všelék. Nemůžeme očekávat, že ji bude možné aplikovat ve všech případech. Dokonce i tam, kde jí využít můžeme, mohou virtuální rozhraní zastarat, takže je bude nutné definovat znovu a znovu provádět také samotnou virtualizaci. Přesto jsme přesvědčeni, že virtualizace je cenný koncept. Každá úroveň virtualizace bude mít svůj vlastní typ popisu virtualizace, tedy určitý druh reprezentační informace, která sama potřebuje svou vlastní reprezentační informaci.
Ve Wikipedii nejdeme pod heslem „Virtualizace“ [11] dlouhý seznam různých druhů virtualizací. V hesle je rozlišováno mezi:
- virtualizací platformy, zahrnující simulaci virtuálních strojů
- a virtualizací zdrojů, která zahrnuje simulace jednoduchých, složených a rozdělených zdrojů.
Uchovávání digitálních informací se zaměřuje na budoucí využití něčeho, co tou dobou budou nesrozumitelné digitální objekty. e-Science (či GRID) se zabývá současným využitím digitálních objektů (bez ohledu na to, zda tyto digitální objekty byly vytvořeny před několika stoletími či před několika sekundami). A právě u těchto objektů hrozí v budoucnu nesrozumitelnost, už jen kvůli množství zdrojů informací, které se stává dostupným. Domníváme se, že reprezentační informace, která podporuje automatizaci a je shromažďována pro účely uchovávání, zároveň uspokojuje potřeby e-Science, konkrétně přetváření souborů bitů na informaci, s kterou pak lze automatizovaně nakládat.

Obr. č. 5: Tok informací v infrastruktuře vytvářené v rámci projektu CASPAR
Obr. č. 5 detailněji znázorňuje množství vrstev, v nichž projekt CASPAR předpokládá využití virtualizace: skladiště digitálních objektů, informace pro jednotlivé disciplíny, společné informace, znalosti vyšší úrovně, řízení přístupu, správa digitálních práv a další procesy.
Shrnutí
Projekt CASPAR se pokouší o exaktní použití konceptů modelu OAIS v největším možném rozsahu, případně je tam, kde je to vhodné, doplňuje. Zároveň jsou zjišťovány meze jejich použití. Neméně významné bylo vytvoření měřítek pro validaci. Další podrobnosti jsou k dispozici na webových stránkách projektu CASPAR, tedy na adrese http://www.casparpreserves.eu/.
[1] http://public.ccsds.org/publications/archive/650x0b1.pdf [cit. 11 June 2007]
[2] http://www.lockss.org/lockss/Home
[3] CASPAR Description of Work http://www.casparpreserves.eu/Members/metaware/ReferenceDocuments/caspar-description-of-work/at_download/file, tab. 1 - Digital Preservation Metrics
[4] Viz např. http://www.bbc.co.uk/radio4/science/findlistenlabel/?programme=allinthemind20070410 [cit. 11 June 2007]
[5] http://www.casparpreserves.eu/Members/cclrc/Deliverables/caspar-conceptual-model-phase-1-1/at_download/file [cit. 11 June 2007]
[6] http://twiki.dcc.rl.ac.uk/bin/view/Main/DCCApproachToCuration
[7] http://www.dcc.ac.uk
[8] Y. Tzitzikas, „Dependency Management for the Preservation of Digital Information", 18th International Conference on Database and Expert Systems Applications, DEXA’2007, Regensburg, Germany, September 2007 (dostupné také na World Wide Web: http://www.ics.forth.gr/~tzitzik/publications/Tzitzikas_2007_DEXA.pdf, pozn. red.)
[9] Y. Tzitzikas and G. Flouris, „Mind the (Intelligibility) Gap", 11th European Conference on Research and Advanced Technology for Digital Libraries, ECDL’2007, Budapest, Hungary, September 2007 (dostupné také na World Wide Web: http://www.ics.forth.gr/~tzitzik/publications/Tzitzikas_2007_ECDL.pdf, pozn. red.)
[10] http://www.dcc.ac.uk/events/warwick_2005/Warwick_Workshop_report.pdf
[11] http://en.wikipedia.org/wiki/Virtualization