Vyhledávače jako nástroje pro měření sémantické podobnosti a vzdálenosti slov
"Jak může vědět část o celku?"
Blaise Pascal
S nástupem internetu a s růstem výpočetní síly počítačů dochází i v informační vědě k proměnám, které reflektují obrovský nárůst informací dostupných ve světových sítích. Klasické postupy informační vědy tak nacházejí uplatnění ve zcela nových oblastech. Jednou z nich je zkoumání tzv. kolektivní inteligence (collective intelligence). Tu definuje Handbook of Collective Inteligence [1] jako "groups of individuals doing things collectively that seem intelligent". Podle autorů Handbooku je oblast kolektivní inteligence rozevřena od biologie přes ekonomii až po informační vědu a umělou inteligenci.
Více než pokusy o akademickou definici možná pomohou příklady uplatnění kolektivní inteligence v našem okolí. Prvním případem je mraveniště, které funguje díky jednoduchým principům průměrování, zpětné vazby a dělby práce. "Průměrování proto, že feromonová stopa se vrství při průchodech jednotlivých mravenců, kteří zároveň – nemají-li nazbyt – prozkoumávají náhodně okolí, a tedy mají celkovou úlohu mezi sebou rozdělenu, přičemž jakmile potravu naleznou, dochází k posilování stopy, a tím i k pozitivní zpětné vazbě." [2]
Pokud jde o svět internetu, uvádí se obvykle jako příklad encyklopedie Wikipedia. Ta vzniká společným psaním a vzájemným redigování textů od různých autorů počínaje nadšenci a konče profesionály. Výsledkem je dnes v anglické verzi více než 3,5 milionu hesel. Často diskutovaná otázka kvality textů v kolektivní encyklopedii v porovnání s texty psanými přímo odborníky byla podrobena testu v časopisu Nature. Ukázalo se, že Wikipedia je přibližně stejně spolehlivá jako slavná Britannica. [3]
Posledním naším příkladem je využití aplikace Google Insight pro predikci míry nezaměstnanosti. Služba nabízí statistiky vyhledávání klíčových slov na internetu za posledních pět let. Vědci Nikolaos Askitas a Klaus F. Zimmermann z Forschungsinstitut zur Zukunft der Arbeit publikovali v Applied Economics Quarterly studii pod názvem Google Econometrics and Unemployment Forecasting [4], ve které ukazují, jak analýza trendů vyhledávání klíčových slov spojených s hledáním práce dokázala predikovat vývoj míry nezaměstnanosti v zemi.
Tyto příklady ukazují, jak lze docházet k velice zajímavým praktickým výsledkům v systému, jehož části o sobě v celku neví, a přesto se všechny na výstupu podílejí. Pro následující práci je důležitý zejména poslední příklad, který využívá běžného lidského chování (hledání práce) k predikci reálného stavu společnosti (míry nezaměstnanosti). Svou pozornost ale zaměřuji jiným směrem. Rád bych ukázal, jak se projevuje zkoumání kolektivní inteligence v oblasti jazykové sémantiky a pragmatiky s využitím klasických přístupů informační vědy a současných vyhledávačů.
V první části se budu věnovat konceptům měření podobnosti mezi slovy pomoci vyhledávačů. V části druhé se věnuji konceptu informační vzdálenosti realizované v tzv. normalized Google distance, pro jejíž měření jsem vytvořil jednoduchou a volně dostupnou webovou aplikaci. Třetí část je věnována možné teoretické implikaci hypotézy kolektivního vědomí. Čtvrtá část pak naznačí, jak postoupit od zkoumání sémantiky ke zkoumání pragmatiky jazyka, a to opět za použití vyhledávačů.
1. Měření podobnosti mezi slovy pomocí internetových vyhledávačů
Informační věda dokáže efektivně využívat relativně jednoduché postupy z matematiky, ať jsou jimi principy z teorie shluků (klastrů), grafů, kombinatoriky či teorie pravděpodobnosti a statistiky [5]. S nástupem internetu a s ním spojené problematiky vyhledávání dostává informační věda nečekané možnosti právě v oblasti aplikace běžných postupů, které využívala již v minulosti.
V posledních letech se objevilo několik pokusů o využití teorie pravděpodobnosti v kombinaci s výsledky vyhledávačů k měření podobnosti slov či frází. Vycházejí z představy, že internet lze chápat jako jeden obrovský korpus, který díky své velikosti může odrážet poměrně stabilní psaný projev "připojeného lidstva". Pokud učiníme tento krok, můžeme právě s internetem začít pracovat běžnými metodami informační vědy, korpusové lingvistiky či statistiky.
Možnost měřit podobnost mezi slovy se vztahuje ke změně v chápání podobnosti. Oproti platónskému (nebo platonizujícímu) výkladu podobnosti jako nápodoby originálu pracují současné teorie podobnosti s myšlenkou porovnávání průniků souboru vlastností mezi objekty. Stanovení těchto vlastností a míra jejich průniku jsou totiž klíčové pro možnost kategorizace. Kategorie a jejich hierarchie totiž vytváříme právě na základě stanovené míry sdílení některých vlastností ve zvoleném pohledu. [6]
Hahn definuje podobnost mezi dvěma reprezentacemi jako míru složitosti vyžadovanou pro transformaci jedné reprezentace v druhou. [7] Jiným vyjádřením téhož principu je definice informační distance mezi X a Y. Vitányi o ní hovoří jako o délce nejkratšího programu hypotetického univerzálního počítače, která transformuje X v Y. [9] Kdybychom chtěli použít slovníku kritika podobnosti jako mimesis Nelsona Goodmana, mohli bychom říci, že dva světy jsou si tím podobnější, čím méně složitých změn je třeba k převodu jednoho v druhý. Samotný Goodman ovšem o takovémto pojetí neuvažoval.
Z takto viděného úhlu jsou výskyty dvou slov ve stránkách indexem jejich náležitosti k nějaké stejné kategorii (kategoriím), díky které jsou spolu v souvýskytu. Roste tak pravděpodobnost jejich podobnosti. A právě údaje o počtu výskytů slov a jejich společném výskytu jsou údaje, které internetové vyhledávače běžně poskytují. Předmětem našeho zájmu budou dvě různé variace kvantitativního zkoumání podobnosti (vzdálenosti) mezi slovy pomocí vyhledávačů. Tím první bude měření podobnosti, druhým pak měření vzdálenosti.
Hlavní metody měření podobnosti slov shrnuje studie Measuring Semantic Similarity between Words Using Web Search Engines [8]: jedná se o WebJaccard, WebOverlap, WebDice a WebPMI, které pro prostředí internetu upravují Jaccardův index, Simpsonův koeficient (WebOverlap), Diceův koeficient a Pointwise mutual information:
fx = počet výskytů slova x
fy = počet výskytů slova y
fxy = počet souvyskytů x a y
n = počet celkově indexovaných stránek
WebJaccard: fxy/((fx+fy)-fxy)
WebOverlap: fxy/min(fx,fy)
WebDice: (2*fxy)/(fx+fy)
WebPMI: log10((fxy/n)/(fx/n*fy/n))
Dále se k nim přidávají metody Sahami, CODC a Proposed SemSim. Ty nevyužívají běžný souvýskyt, ale obsah takzvaných snippetů, tedy vyhledávačem vráceného příkladu souvýskytu. Například pro dotaz ”cricket” AND ”sport” vrací vyhledávač Google snippet ze stránky Wikipedie o tomto obsahu:
"Cricket is a sport played predominantly in the drier periods of the year."
Autoři studie uvádějí, že takové snippety indikují silný souvýskyt mezi slovy, ať již se jedná o typ vztahu být příkladem či částí nebo společného nadřazeného pojmu a další. V těchto případech již bylo třeba postupovat komplikovaněji a autoři vytvářeli mikroprogramy určené k identifikaci vztahu mezi pojmy postupným variováním různých n-gramů, jako např. "X and Y", "X and Y are", "X and Y are two" nebo "X is a Y".
Autoři studie porovnávali výsledky vzorců a algoritmu s Miller-Charlesovým datovým souborem, který obsahuje 30 párů slov hodnocených 38 lidmi. Jednotlivé páry slov jsou v něm ohodnoceny na škále 0 (žádná podobnost) až 4 (synonymum). Výsledky byly více než překvapivé, když metodologie Proposed SemSim dosáhla korelace s lidským hodnocením 0,834.
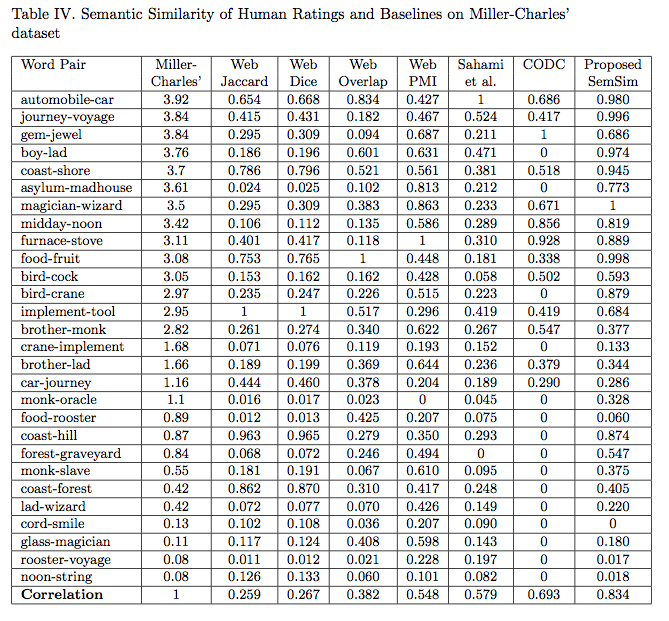
Tabulka zobrazující sémantickou podobnost (tzv. SemSim) u vybraných párů slov
2. Informační vzdálenost: normalized Google distance
Výborné výsledky algoritmů postavených na práci se snippety jsou bohužel vykoupeny vstupem lidského faktoru do způsobu extrakce dat, kdy je třeba nejdříve stanovit vzorce (patterns) pro vztahy a dále s nim pracovat. Toto omezení obchází využití teorie informační vzdálenosti (information distance) v kombinaci s vyhledávači známé jako normalized Google distance. Autory této koncepce jsou Rudi Cilibrasi a Paul M. B. Vitanyi, kteří ji shrnuli ve studii The Google Similarity Distance [9].
Google normalized distance je vyjádřená vzorcem
m = log10(počet všech indexovaných stránek);
fx = log10(počet výsledků pro slovo X);
fy = log10(počet výsledků pro slovo X);
fxy = log10(očet výsledků pro slovo X a Y);
GND = ((max(fx,fy) - fxy) / (m - min(fx,fy))
přičemž do úvahy se bere prostý souvýskyt na stránce výsledku, nikoli vzdálenost slov mezi sebou na stránce. Pro normalizaci do intervalu (většinou) mezi 0 - 1 je využíváno Kologromorovy komplexity. Čím více je číslo blíže nule, tím jsou si dvě slova podobnější.
Cilibrasi a Vitanyi podrobili svůj vzorec celé řadě testů - mezi nimi jsou i shlukování malířů a spisovatelů, shlukování čísel a barev, ale také komparace výsledků s WordNetem. Všechny experimenty přinesly pozoruhodné výsledky. Systém byl schopen vytvořit mapy shluků s velkým úspěchem, a to jak v případě barev a čísel, tak i v případě anglických spisovatelů:
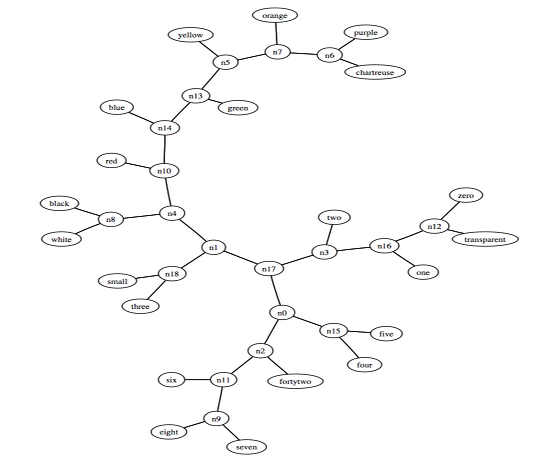
Mapa shluků barev a čísel

Mapa shluků spisovatelů a jejich knih
Pozoruhodně dobrých výsledků dosáhla metoda při komparaci s anglickým WordNetem. Pokud šlo o určení vzdálenosti slov zařazených do stejné větve WordNetu, měl NGD 100% úspěšnost. Cilibrasi s Vitanyim šli ve svém experimentu ještě dál a pomocí strojového učení a pozitivních a negativních souborů slov z kategorií WordNetu vytvořili systém pro klasifikaci nových slov. Úspěšnost klasifikátoru oproti WordNetu byla 87 %.
3. Teoretické implikace: kolektivní vědomí
Na základě tohoto teoretického konceptu jsem vytvořil webovou aplikaci Mechanical Cinderella. Jejím základem je koncept Normalized Google Distance. Vzorec jsem ovšem upravil o simulaci vyhledávání nikoli pouhého souvýskytu, ale o blízkost plus minus šest slov, což při skutečnosti, že Google nezapočítává do slov spojky a ukazovací zájmena, znamená příbližně výskyt v okolních větách.
Mechanical Cinderella je naprogramována v PHP a využívá REST API pro Google Search. V době vývoje jsem ji testoval i pro vyhledávač Yahoo!, přesněji pro jeho YAHOO Boss Search API, které není limitováno takovými omezením licence jako Google Search, má však k dispozici o něco menší počet stránek.
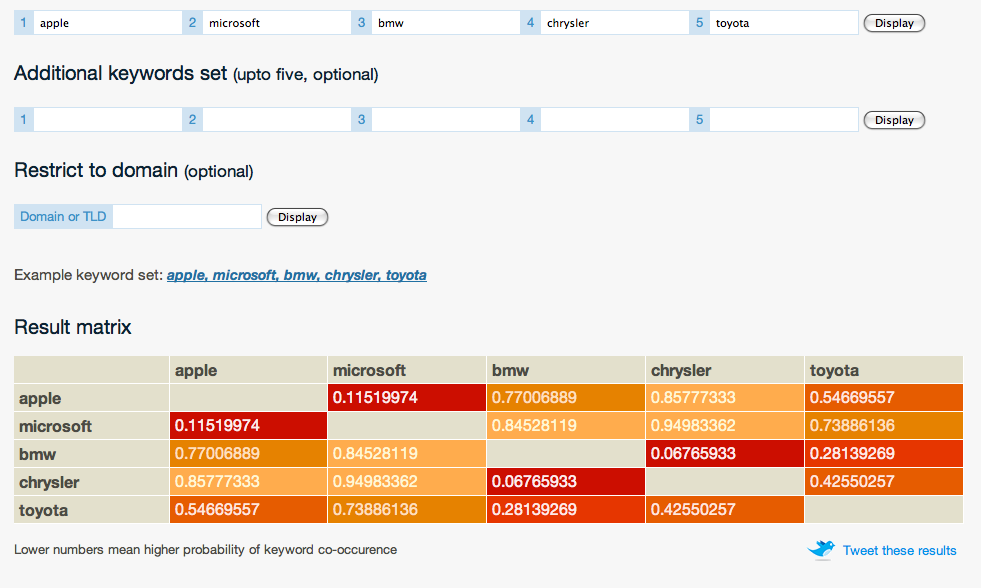
Náhled výsledků aplikace Mechanical Cinderella
Aplikaci jsem testoval na několik různých příkladech, nejklasičtějším z nich (podle kterého dostala aplikace i jméno - viz blogpost K čemu je dobrá Mechanická Popelka) je úloha, při které má matice zaznamenat blízkost značek dvou internetových a tří automobilových firem a následně provést jejich shlukování podle vzdálenosti mezi sebou.
Za značky byly vybrány: Google, Yahoo, Chevrolet, Jaguar a BMW s následujícím výstupem:
|
yahoo |
chevrolet |
jaguar |
bmw |
|
|
0.23108465 |
0.91864247 |
1.03448318 |
0.87848597 |
|
yahoo |
0.23108465 |
|
0.93487686 |
1.02524878 |
0.87022126 |
chevrolet |
0.91864247 |
0.93487686 |
|
0.19829 |
0.06866132 |
jaguar |
1.03448318 |
1.02524878 |
0.19829 |
|
0.34200698 |
bmw |
0.87848597 |
0.87022126 |
0.06866132 |
0.34200698 |
|
Pokud nastavíme míru shluku jako blízkost pod 0,35, vytvoříme dva silné shluky: Google a Yahoo na jedné straně a Chevrolet, Jaguar a BMW na druhé. Princip tak funguje stejně jako v příkladech autorů GND.
Pokud se podíváme na způsob verifikace obou zmíněných experimentů, musíme u nich ocenit silný důraz na ověření dat vůči lidsky testovanému vzorku. V prvním případě je soubor "testovaný" na lidech, v případě druhém je to WordNet, tedy lidmi vytvořená sémantická síť.
Domnívám se ovšem, že je možné jít ještě o krok dál - pokusit se posunout pohled na webový korpus a pokusit se ho chápat jako určité kolektivní vědomí ve smyslu totality postojů a přesvědčení společnosti, ve kterém jsou zahrnuty individuální postoje a přesvědčení. Takto uchopené kolektivní vědomí potom může být předmětem dalšího zkoumání.
|
Acer |
Asus |
Dell |
Sony |
|
netbook |
0.35800007 |
0.3266841 |
0.45478901 |
0.47944917 |
|
notebook |
0.26631807 |
0.40387194 |
0.4695783 |
0.37106721 |
|
best |
0.82109866 |
0.77081225 |
0.49510104 |
0.45805274 |
|
worst |
1.05309145 |
1.08005446 |
1.03558973 |
0.95438995 |
|
Kolektivní vědomí reprezentované webovým korpusem může být i úspěšně filtrováno podle jazyků a tím častečně podle státních celků. Pro češtinu vychází dovolená jako silně asociovaný pojem s Chorvatskem či Bulharskem, zatímco Rusko, Polsko a Angola jsou zcela mimo.
|
Chorvatsko |
Bulharsko |
Rusko |
Polsko |
Angola |
dovolená |
0.28532696 |
0.31441792 |
0.638793 |
0.67618915 |
1.31600954 |
Pokud ale vygenerujeme podobné tabulky pro angličtinu, budou tyto rozdíly významně potlačeny:
|
Croatia |
Bulgaria |
Poland |
Russia |
Angola |
holiday |
0.80741094 |
0.84635841 |
0.9426911 |
0.86722447 |
1.16940688 |
V případě němčiny se náklonost německých turistů k Chorvatsku projeví víc, nikoli ovšem k Bulharsku:
|
Kroatien |
Bulgarien |
Polen |
Russland |
Angola |
Urlaub |
0.44202144 |
0.66766379 |
1.01710988 |
0.66693234 |
1.27975176 |
4. Další možnosti: pohled z druhé strany
Síla i slabost informační vzdálenosti i podobnosti slov spočívá hlavně v tom, že relativně vícerozměrnou sémantiku redukují do jedné dimenze. Zjednodušeně řečeno: webový korpus obsahuje sedliny všech textů bez jejich časového, žánrového či jiného rámce, a tak samotný význam souvýskytu musí být dále interpetován.
Navíc u příkladu s dovolenou a Chorvatskem nastávají další problémy. Jaký je vztah mezi vlastním jménem a běžným podstaným jménem? Viděli jsme, že vazba mezi Chorvatskem a dovolenou byla typická pro češtinu, avšak pro němčinu a angličtinu nikoli.
Otázkou tedy zůstává, zda je možné strojově pracovat s dalšími možnostmi, které vyhledávání nabízí, a přidávat tak další kritéria.
Jednou z možností je zřejmě porovnání informační vzdálenosti s frekvencí vyhledávání. Jinými slovy: zabývat se nejen samotným webovým korpusem, ale i způsobem, jak k němu lidé přistupují, jak se ho ptají, jaká slova zadávají do vyhledávače, aby získali požadovanou odpověď.
Pokud bychom k tomu chtěli přikročit ze strukturalistických pozic, je každé hledání ukázkovým výběrem na paradigmatické ose. Díky službě Google Insight můžeme sledovat křivky vyhledávání slov či frází za určené období a sledovat tak jejich korelaci v čase. Zkusme se podívat z tohoto pohledu zpět na příklad s dovolenou a jednotlivými destinacemi a porovnejme si tabulku GND s křivkami hledání.
|
Chorvatsko |
Bulharsko |
Rusko |
Polsko |
Angola |
dovolená |
0.28532696 |
0.31441792 |
0.638793 |
0.67618915 |
1.31600954 |
Výsledky křivky hledání
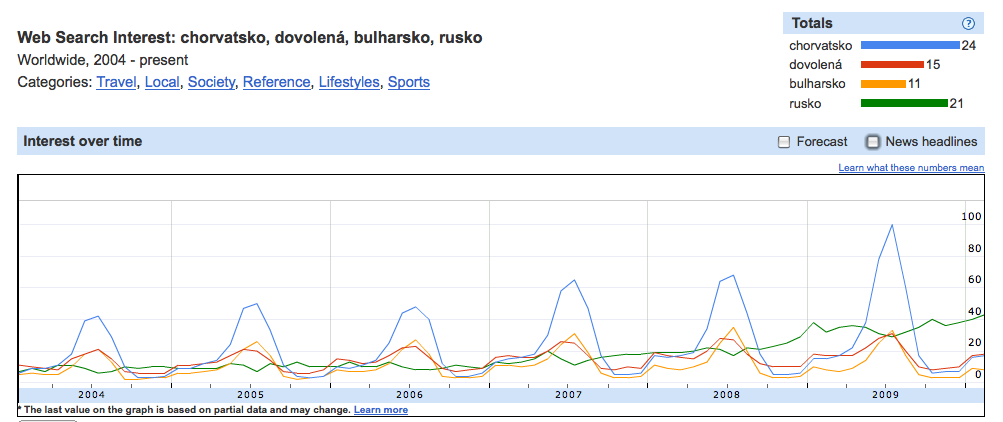
Výsledky křivky hledání vybraných slov
Vidíme, že křivky hledání slova dovolená, Bulharsko a Chorvatsko se prakticky kryjí, zatím co křivka hledání pro Rusko se chová zcela nezávisle. Můžeme z toho formulovat hypotézu, že v určitých časových okamžicích máme slova Chorvatsko či Bulharsko za skoro synonymická se slovem dovolená.
Nepřímým testem může být i statistika hledaných dvouslovných údajů z nápovědy v Google Search. Při psaní dotazu do vyhledávací políčka totiž Google vrací často hledaná slova k doplnění psaného dotazu. Také zde se nám potrzují předpokládané korelace.
Seznam nejčastěji hledných sousloví obsahující první slovo dovolená:
- dovolená 2010
- dovolená last minute
- dovolená s dětmi
- dovolená chorvatsko
- dovolená itálie
- dovolená egypt
- dovolená řecko
- dovolená v čechách
- dovolená léto 2010
- dovolená chorvatsko 2010
Seznam nejčastěji hledných sousloví obsahující první slovo chorvatsko
- chorvatsko 2010
- chorvatsko ubytování
- chorvatsko dovolená
- chorvatsko mapa
- chorvatsko apartmány
- chorvatsko počasí
- chorvatsko český slovník
- chorvatsko eu
- chorvatsko.cz
- chorvatsko český slovník online
Seznam nejčastěji hledných sousloví obsahující první slovo bulharsko
- bulharsko jana z rychlých prachů
- bulharsko dovolená
- bulharsko 2010
- bulharsko jana
- bulharsko primorsko
- bulharsko autem
- bulharsko český slovník
Seznam nejčastěji hledných sousloví obsahující první slovo rusko
- rusko český slovník
- rusko český slovník online
- rusko japonská válka
- rusko wiki
- rusko mapa
- rusko dnes
- rusko počet obyvatel
- rusko finská válka
- rusko vánoce
- rusko vízum
Seznam nejčastěji hledných sousloví obsahující první slovo polsko
- polsko český slovník online
- polsko český slovník
- polsko zajímavosti
- polsko wiki
- polsko měna
- polsko mapa
- polsko počet obyvatel
- pol skone
- polsko turistika
- polsko dálnice
Ještě zajímavější výsledky dostaneme v dalším příkladě, kde máme k dispozici dva silné shluky. Na jedné straně tu máme shluk mp3 / ipod / music a na straně druhé apple / microsoft (apple a ipod mají silnou vazbu, protože ipod je výrobek apple), přičemž mezi slovy apple a music, případně mezi slovy microsoft a ipod máme relativní blízkost.
|
mp3 |
ipod |
music |
apple |
microsoft |
mp3 |
|
0.37696209 |
0.27682576 |
0.59834686 |
0.70880659 |
ipod |
0.37696209 |
|
0.13211756 |
0.11706145 |
0.4342487 |
music |
0.27682576 |
0.13211756 |
|
0.42113737 |
0.69099775 |
apple |
0.59834686 |
0.11706145 |
0.42113737 |
|
0.11705376 |
microsoft |
0.70880659 |
0.4342487 |
0.69099775 |
0.11705376 |
|
Když zvolená slova zobrazíme na časové ose, vidíme, že přibližně od poloviny roku 2006 se shodují špičky pro hledání mezi mp3, ipod a music, zatímco ostatní shluky podobnou korelaci nevykazují. Můžeme z toho vyvodit hypotézu, že se jedná o pojmy, které k sobě mají spíše souřadný vztah. Bylo by to ale zapotřebí dále ověřit.
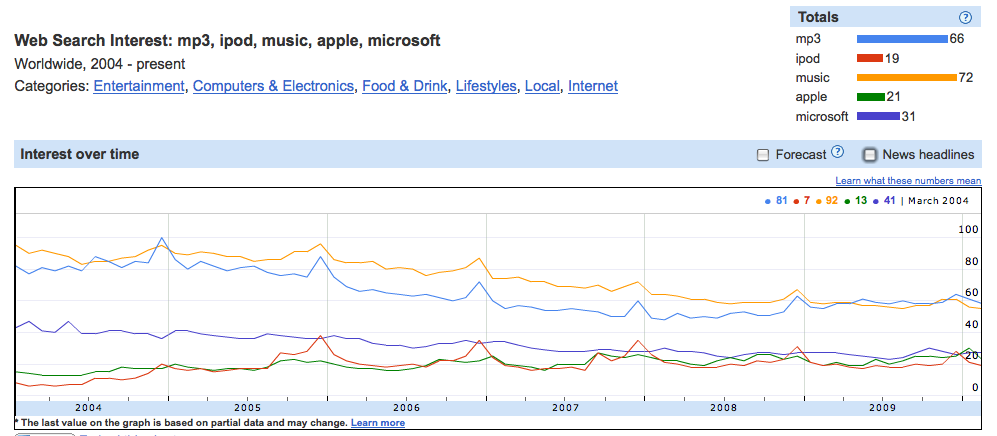
Výsledky křivky hledání vybraných slov
5. Závěr
Na výše uvedených příkladech jsme viděli, že koncepce kolektivní inteligence - demonstrovaná na existenci webového korpusu na jedné straně a možností, které nabízí vyhledávače, na straně druhé - otevírá pro informační vědu nové obzory, v nichž se aktualizují starší postupy z informační vědy. Přitom oblast uplatnění nových poznatků zahrnuje jak akademické oblasti (lingvistika, sémantika, ale i sociologie), tak oblasti praktické, jako je marketing.
[1] Handbook of Collective Inteligence. URL: http://scripts.mit.edu/~cci/HCI
[2] Heslo Kolektivní inteligence, URL: http://cs.wikipedia.org/wiki/Kolektivní_inteligence
[3] Jim Giles. Internet encyclopaedias go head to head. in Nature 438, 900-901 (15 December 2005).
[4] Nikolaos Askitas, Klaus F. Zimmermann. Google Econometrics and Unemployment Forecasting. Applied Economics Quarterly, 2009, 55 (2), 107-120.
[5] Marie Königová a kol. Matematické a statistické metody v informatice. Praha : SPN, 1988.
[6] Danushka Tarupathi Bollegala. A Study on Attributional and Relational Similarity between Word Pairs on the Web. 2009 PhD Tesis on The University of Tokyo
[7] Ulrike Hahn, Nick Chater, Lucy B. Richardson. Similarity as transformation. Cognition 87 (2003) 1–32
[8] Danushka Bollegala, Yutaka Matsuo a Mitsuru Ishizuka. Measuring Semantic Similarity between Words Using Web Search Engines. WWW 2007, May 8–12, 2007, Banff, Alberta, Canada.
[9] Rudi Cilibrasi a Paul M. B. Vitanyi. The Google Similarity Distance. IIEEE Transactions on Knowledge and Data Engineering, vol. 19, no. 3, March 2007, 370–383