NEDLIB Harvester
Publikování informací na Internetu, které se stalo velmi rychle samozřejmou součástí každodenní praxe, přináší nejen množství nových možností, ale i řadu problémů. Jedním z takových problémů, na jehož řešení spolupracují již několik let národní knihovny řady západoevropských zemí v rámci projektu NEDLIB (Networked European Deposit Library), je i problém realizace povinného výtisku elektronických publikací dostupných na Internetu.
Je zřejmé, že v případě on-line elektronických publikací, které se stále častěji stávají zdrojem jinde nepublikovaných informací, se nelze pasivně spolehnout na to, že knihovna automaticky obdrží jejich kopii. Pokud má knihovna zájem na uchování této části národního dědictví, musí být aktivita na její straně. Situaci knihovnám usnadňuje fakt, že drtivá většina on-line publikovaných informací je přístupná pomocí malého počtu komunikačních protokolů (především HTTP, FTP a NNTP) a je uložena v překvapivě malém množství formátů. Například podle výzkumů Švédské královské knihovny je přibližně 95 % on-line dokumentů publikováno ve čtyřech základních formátech: HTML, ASCII (čistý text bez formátování), JPEG a GIF; pátým nejrozšířenějším formátem se stává PDF.
Společným jmenovatelem všech těchto dokumentů je to, že je možno je automatizovaně stáhnout do webového archivu příslušné národní knihovny a poté definovaným způsobem opět zpřístupnit. Tak by bylo možné archivem procházet podobně, jako by šlo o původní web, ale se zohledněním časového údaje (budoucí badatel by tak například získal možnost prohledávat a procházet celý český web tak, jak vypadal mezi lety 2001 a 2003).
Projekt NEDLIB stanovil proto pro tuto oblast jako prioritní úkol vyvinutí nástroje pro archivaci informačních zdrojů Internetu. Samotný princip takového nástroje (jeho anglický název harvester by se dal přeložit do češtiny jako kombajn) není ničím převratný, protože první aplikace tohoto typu byly vyvinuty již kolem roku 1994. Jejich funkce je jednoduchá: na základě předem daného seznamu adres stáhnou první dávku dokumentů. Ty jsou podrobeny analýze s cílem najít v nich obsažené odkazy na další stránky. Ty jsou následně také staženy a celý proces je opakován tak dlouho, dokud nejsou staženy a analyzovány všechny stránky z předem definované oblasti. Tento proces lze samozřejmě rozšířit i na celý Internet; ten je ale tak rozsáhlý, že by vytvořený archiv nikdy nemohl být kompletní a aktuální.
Běžné harvestery obvykle stažené dokumenty nearchivují a po zaindexování je zahazují. Myšlenka použít modifikovaný harvester k archivaci webu vznikla ve Švédsku, kde v roce 1996 začali v rámci projektu Kulturarw3 vyvíjet nástroje pro archivaci webu. Právě na výsledky tohoto projektu navázal o rok později projekt NEDLIB a projekt severských zemí NWA (Nordic Web Archive). V obou naposledy zmíněných projektech hrála významnou roli Helsinská univerzitní knihovna a finské Center for Scientific Computing (CSC), které vyvinulo na základě specifikací partnerských knihoven současnou verzi programu NEDLIB Harvester. Ta bude v rámci projektu "Registrace, ochrana a zpřístupnění domácích elektronických zdrojů v síti Internet" Národní knihovny ČR v příštím roce vyzkoušena i v prostředí českého webu.
Okrajové podmínky
Základním krokem celého archivačního procesu je vhodná volba okrajových podmínek: stanovení oblasti která má být archivována, definování podoblastí, které budou naopak z archivace vyloučeny, stanovení podporovaných komunikačních protokolů apod.
Zájmovou oblastí bude pro evropskou národní knihovnu obvykle její národní doména (u nás tedy *.cz) a dále informační zdroje v národním jazyce, nebo národně zaměřené informační zdroje v cizích jazycích. Obvykle se takové zdroje nacházejí v doménách .com nebo .net, kde samozřejmě tvoří jen zlomek jejich celkového objemu, může ale být významný při srovnání s celkovým objemem zdrojů v národní doméně (Ve Švédsku se jen 60% archivovaných zdrojů nacházelo v doméně .se). Mimo národní doménu je samozřejmě většinou nutné zájmovou oblast specifikovat podrobněji - je proto možné zakázat nebo povolit jak jednotlivé domény nebo servery, tak i konkrétní adresáře daného serveru.
Dalším důležitým kritériem je volba podporovaných komunikačních protokolů: mimo samozřejmou podporu protokolu HTTP (verze 1.1) je podporován i protokol FTP. Jeho využívání je ale omezeno jen na ty soubory, na něž vede přímý odkaz z webu. Toto omezení je nutné kvůli tomu, že většina souborů přístupných přes FTP je zahraničního původu - zde lze zmínit například rozsáhlá zrcadla zahraničních ftp serverů na serverech českých univerzit. Harvester je samozřejmě při znalosti jména a hesla schopen přistupovat i na servery vyžadující autentifikaci. Poslední významný protokol, NNTP, nebyl do množiny podporovaných protokolů zahrnut záměrně, protože se jako schůdnější ukázalo zřídit samostatný news server a v něm definovat ty diskusní skupiny, které jsou z hlediska archivace důležité.
Ačkoli je harvester v současné podobě zaměřen především na sběr statických stránek, je možné zapnout podporu těch URL, které obsahují parametry. V současné době ale neexistuje žádné komplexní řešení, které by umožnilo systematický sběr dynamických stránek. Jedním z možných budoucích řešení, použitelných například u vydavatelů periodik, by mohla být instalace speciální aplikace, která by harvester upozorňovala na všechny nově publikované stránky.
Plánování sběru
Dalším hlediskem, důležitým pro provoz harvesteru, je hledisko časové. Nejde ani tak o to, aby server mnoha paralelními požadavky nepřetěžoval síťovou infrastrukturu, protože kapacita páteřních sítí (zvláště akademických) již není úzkým hrdlem (například odhadovaných 500 GB dat, která by mohla svým objemem odpovídat jedné národní doméně, lze nyní z Prahy do Brna po páteři TEN-155 teoreticky přenést za méně než půl hodiny). Oním důležitým kritériem je především snaha nepřetěžovat jednotlivé sklízené servery a ani ostatní moduly Harvesteru.
Plánovací modul (scheduler) harvesteru řeší tuto problematiku tak, že vkládá prodlevy mezi jednotlivé požadavky na stahování ze stejného serveru. Tyto prodlevy nejsou konstantní, ale mění se podle toho, jaké množství stránek servery obsahují - předpokládá se, že rozsáhlé servery jsou také výkonnější a mají rychlejší připojení k Internetu a snesou proto i větší nápor požadavků, než servery malé.
Z praktických zkoušek vyplynulo, že i tento přístup má svá úskalí: přes větší prodlevy je stahování obsahu malých serverů dokončeno relativně rychle a pak zůstává jen pomalé stahování z několika velmi rozsáhlých serverů. Je proto velmi důležité od začátku dbát na vhodné rozložení požadavků na jednotlivé servery v čase. V nejnovější verzi Harvesteru je toho dosaženo monitorováním rychlosti odezvy jednotlivých serverů a přizpůsobováním jejich zátěže zjištěným hodnotám.
Protože je v zájmu archivující instituce získat co nejúplnější obraz archivované části webu, nestačí pouze jednou za čas provést jednorázový sběr - celý proces by měl naopak být průběžný. Harvester proto podporuje dva režimy sběru: plný a doplňovací (inkrementální). Zatímco v prvním případě se předpokládá při každém průchodu s uložením všech dokumentů, v případě druhém se ukládají pouze ty dokumenty, které se od poslední návštěvy změnily (tuto informaci harvester získá porovnáním kontrolního součtu MD5 archivovaného a nově staženého dokumentu) nebo přestěhovaly na jinou adresu (harvester pak přestěhovaný dokument považuje za nový). Jednou z možností, jak naznačit kontinuitu mezi dvěma různými výskyty dokumentu je použití autorizovaného URN - jednoznačného identifikátoru informačního zdroje.
Je zřejmé, že některé části webu se mění častěji než jiné: server vydavatele denního tisku se bude měnit podstatně častěji, než například server obsahující vědecké publikace. Harvester proto může být spuštěn v několika paralelních verzích, z nichž každá se stará o jinou oblast webu a prochází ji jinou rychlostí.
Stahování
Dokumenty jsou harvesterem stahovány do pracovního adresáře. Zde jsou analyzovány, zpracovány a poté archivovány, většinou pomocí páskového robota.
První pokusy s hromadným stahováním dokumentů ukázaly, že harvester musí být velmi robustní a musí být schopen se korektně vypořádat s mnoha nečekanými situacemi: s HTTP servery, které při komunikaci nepoužívají žádné HTTP hlavičky, nebo s HTML dokumenty s velkým množstvím vložených binárních dat. Zvláště hlavičky HTTP protokolu jsou velmi důležité, protože právě podle nich harvester pozná, zda bylo stahování úspěšně dokončeno.
Pokud stažený dokument obsahuje vložené obrázky, video, applety nebo jiné objekty, musí je harvester stáhnout co nejdříve. To je nutné proto, že kdyby mezi stažením dokumentu a stažením v něm vložených objektů došlo k větší prodlevě, mohly by tyto objekty mezitím zmizet nebo být nahrazeny jinými, což by mohlo celý dokument znehodnotit. Proto musí také harvester při stahování těchto objektů ignorovat hranice zájmové oblasti, která byla pro archivaci vymezena. Všechny objekty jsou archivovány společně s dokumentem.
Každý stažený dokument musí být analyzován a všechny v něm obsažené odkazy, spadající do definované zájmové oblasti, musí být zařazeny do fronty požadavků ke stažení. V praxi samozřejmě není možné analyzovat všechny formáty dokumentů. Harvester dokáže analyzovat textové i HTML soubory, ostatní soubory touto fází neprocházejí, i když do budoucna není vyloučena ani podpora souborů PDF a Postscript.
Harvester musí také brát ohled na omezení uložená v souborech robots.txt na jednotlivých serverech. Jejich cíl, zakázat automatickým prohledávačům v procházení serveru nebo jeho části, se ale v některých případech nemusí krýt se záměrem archivující instituce. Proto je možné tuto vlastnost vypnout buď globálně, nebo pro jednotlivé servery.
Archivace
Dokumenty jsou ukládány výhradně až po jejich úspěšném stažení. Tím je zajištěno, že archivovaný dokument je kompletní. Záznamy o neúspěšných pokusech jsou ukládány do databáze a mohou být využity webmastery pro kontrolu chybných odkazů. Pokud se nepodaří dokument stáhnout napoprvé, zkusí to harvester okamžitě ještě jednou a později pak ještě třikrát. Pak je odkaz prohlášen za mrtvý.
Po úspěšném stažení je do databáze uložen čas ukončení operace a kontrolní součet MD5 staženého dokumentu, který zároveň plní funkci jednoznačného identifikátoru daného dokumentu. Stažený dokument musí být uložen bez jakýchkoli modifikací. Díky tomu je zajištěna možnost opětným výpočtem kontrolního součtu archivovaného dokumentu a jeho srovnáním s původním kontrolním součtem potvrdit identičnost dokumentu. Zároveň tak lze předejít duplicitní archivaci identických dokumentů ze dvou různých URL - obě URL budou ukazovat do stejného místa archivu. Čas ukončení operace je ukládán ve formě tzv. unixového času a musí jít o opakovatelnou položku, díky čemuž je možné zjišťovat, ve kterém období zůstal dokument beze změn.
Harvester musí mimo vlastního dokumentu archivovat i metadata vztahující se k dokumentu a k vlastnímu procesu stahování. Do databáze se proto ukládá nejen jeho URL, ale i všechny informace z hlavičky HTTP a je možné archivovat i metadata obsažená přímo v HTML dokumentu. Všechna ukládaná metadata jsou před uložením převedena do stejné znakové sady.
Samotné dokumenty jsou ukládány v balících po tisíci souborech do souborů komprimovaných pomocí programů tar a gzip. K tomuto řešení se přistoupilo proto, aby bylo možné stažené dokumenty archivovat na velkokapacitních magnetických páskách, které jediné umožňují v současné době cenově dostupnou cestu k archivaci tak velkých objemů dat, jaká jsou harvesterem generována.
Součástí harvesteru není žádný modul pro zpřístupnění vytvořeného archivu. Práce na řešení tohoto úkolu jsou teprve v počátečních stádiích. Již dnes je ale zřejmé že jde o úkol velmi složitý a že vývoj přístupového modulu bude i finančně velmi náročný.
Popis programu
NEDLIB Harvester se skládá z devíti modulů (unixových démonů) a několika pomocných programů (pro vkládání autentifikačních údajů do databáze, pro korektní zastavení všech programů, pro archivaci stažených souborů apod.). Celá aplikace byla původně napsána v jazyce perl, ale později téměř celá přepsána do 10000 řádek jazyka C, čímž bylo dosaženo jejího podstatného zrychlení. Jádrem celého systému je 20 databázových tabulek v databázovém systému MySQL. Ovladače protokolů HTTP a FTP a parser HTML byly převzaty z aplikace wget. Celý systém je šířen bezplatně.
Hardwarové požadavky systému velmi závisí na plánovaném použití. Pro testovací účely a omezený provoz stačí běžný linuxový server s alespoň 512 MB paměti a dostatečně velkým a rychlým diskem (13 GB disk postačí pro stažení a archivaci cca 500.000 souborů). Pro ostrý provoz je však zapotřebí sáhnout hlouběji do kapsy: doporučuje se dvouprocesorový server Compaq/Alpha nebo Sun s alespoň 2 GB paměti, 100 GB na pevných discích a páskový robot s kapacitou nejméně 1 TB.
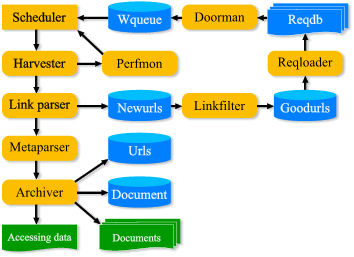
Obr. 1 Funkční schéma programu NEDLIB Harvester
Princip celé aplikace je relativně jednoduchý: Scheduler - hlavní proces celého systému, sděluje jednotlivým procesům modulu Harvester kdy a kde požadovat soubory k archivaci. Tyto informace jsou čerpány z tabulky Wqueue, kam zároveň jednotlivé Harvestery vrací nevyřízené požadavky k opakovanému stažení. Modul Perfmon monitoruje rychlost odezvy jednotlivých serverů a zpětnou vazbou informuje Scheduler o potřebných úpravách jejich zátěže.
Textové a HTML dokumenty zpracovává Link parser - hledač odkazů, který všechny odkazy nalezené v analyzovaných dokumentech uloží do tabulky Newurls. Stejné dokumenty dále zpracovává Metaparser, sestávající z několika aplikací, které ze zpracovávaných dokumentů extrahují metadata.
Všechny stažené dokumenty se pak sejdou v modulu Archiver. Ten rozhoduje, zda byl stažený soubor už někdy stažen a zajišťuje archivaci jak samotných dokumentů, tak i příslušných metadat: do souboru Accessing data se tyto údaje ukládají pro účely archivace a do tabulek Urls a Documents z provozních důvodů.
Odkazy z tabulky Newurls zpracovává Link filter který propouští do tabulky Goodurls jen ty odkazy, které splňují kritéria pro archivaci. Tyto odkazy zpracovává Reqloader, který vytváří samostatné seznamy požadavků na jednotlivé servery (Reqdb). Z těch pak na žádost Scheduleru dávkově čerpá modul Doorman.
Ačkoli je rutinní používání NEDLIB Harvesteru v evropských národních knihovnách zatím v počátcích, má už v různých zemích na svém kontě stovky gigabajtů stažených dokumentů. Je velmi pravděpodobné, že již příští rok dojde k první pokusné "sklizni" i u nás. Pokud se tento systém osvědčí, začne být i pro nás aktuální komplexní problematika zpřístupnění vytvořeného archivu.