Digitalizace lístkové kartotéky Retrospektivní bibliografie české literatury
1. Retrospektivní bibliografie české literární vědy
Jedním z nejcennějších sbírkových fondů uchovávaných v Ústavu pro českou literaturu AV ČR je bezesporu tzv. Retrospektivní bibliografie české literatury, která je v podobě lístkové kartotéky zpracovávána po dobu více než 60 let. Pro tuto kartotéku byly excerpovány články z periodik a denního tisku vycházejícího na území českých zemí v češtině i němčině, které se tematicky dotýkají literatury a literární vědy včetně otisků beletrie a literárních překladů – celkem bylo takto zpracováno cca 530 titulů vycházejících v letech 1775-1945.
Za dobu své existence se retrospektivní bibliografie rozrostla v rozsáhlý katalog, jehož velikost byla odhadována na cca 1,75-2 miliony excerpčních lístků. Skutečný počet jedinečných excerpt je zhruba poloviční, neboť záznam o tomtéž článku mohl být zařazen dle příslušných kritérií do různých částí kartotéky: takto byly vyděleny části autorská s návaznou částí dešifrační, do níž byly vyčleněny záznamy nedešifrovaných autorů, části předmětová-osobní a předmětová-věcná a k nim analogické ikonické části, evidující obrazové materiály (fotografie literárních osobností, karikatury, ilustrace k literárním dílům atp.). Toto dělení samozřejmě znamenalo velké časové nároky na průběžnou redakci, v poslední době zaměřenou především na rozklíčování autorství článků podepsaných šiframi (i tak zůstává nedešifrováno cca 13 % z celku autorských excerpt).
Kartotéka po dlouhou dobu sloužila především ústavním výzkumným úkolům (je mimo jiné podkladem bibliografických soupisů v Lexikonu české literatury) a širší veřejnosti byla dlouho přístupná pouze prostřednictvím osobní návštěvy v ústavu. V 90. letech byl učiněn pokus o její převedení do strukturované databázové podoby, v jehož rámci byla převedena část předmětové části. Tento projekt však časem ustrnul: jeho výsledkem je celkem cca 90 000 databázových záznamů dostupných jako databáze RET.
Digitalizace ručním přepisem se však ukázala jako časově, personálně a především finančně velmi náročná a nebylo v silách ústavu pokračovat touto cestou digitalizace z vlastních zdrojů. Orientační hrubé kalkulace odhadovaly databázový přepis kartotéky minimálně na 30 let práce pro 1 osobu na plný úvazek. Potřeba zpřístupnit kartotéku širší veřejnosti byla nicméně pociťována jako stále silnější a v roce 2009 tak byl vypracován projekt na její digitalizaci skenováním, který byl následně podán do programu INFOZ Ministerstva školství, mládeže a tělovýchovy ČR. V září téhož roku byla žádost ze strany MŠMT schválena a práce na digitalizaci kartotéky jako projekt VZ09004 mohly začít. Předběžné rozvahy o možné podobě budoucího softwarového řešení tak dostaly konkrétnější podobu.
2. Projekt digitalizace retrospektivní bibliografie
2. 1. Analýza dat a hardwarové zajištění
Prvotní fáze analýzy se týkaly především samotných excerpčních lístků a návrhu jejich co nejjednoduššího a nejefektivnějšího strojového zpracování a s tím spojeného výběru vhodného skeneru. Už v tomto momentě bylo třeba vyřešit několik zdánlivě podružných, avšak ne zcela triviálních záležitostí. V průběhu času byly totiž při excerpci použity nejrůznější druhy papíru: od tenkého průklepového používaného při kopírování totožných záznamů do různých částí kartotéky až po tvrdší a silnější kartotéční lístky. Zároveň katalog obsahoval jak lístky psané po jedné straně, tak po obou stranách a zároveň i lístky vícelístkové.

Originál skenu excerpčního lístku
Hledali jsme tedy skener, který by umožňoval souběžné oboustranné skenování excerpčních lístků, měl automatický podavač se spolehlivou citlivostí na lístky různé tloušťky a lístek jím pokud možno procházel po jedné linii bez otáčení. Při pokusném skenování na skenerech s nelineární drahou průchodu se nám totiž v místech ohybů lístky zasekávaly, či dokonce trhaly. Z nabízených možností se nám jako nejlepší nakonec jevil skener Fujitsu-Siemens 6140, který naše vstupní představy beze zbytku splňoval a nadto byl i poměrně cenově dostupný. Výkonnost tohoto skeneru se pohybovala při oboustranném skenování na rozlišení 600*600 dpi okolo 15 lístků za minutu, při rozlišení 300*300 stoupá i k 50. Zde nutno předeslat, že jsme na skeneru zvládli během cca dvou let seskenovat bez větších potíží celou kartotéku retrospektivy včetně dalších lístkových katalogů ÚČL, celkem takřka 2 miliony kartotéčních lístků, přičemž bylo třeba jen několikrát vyměnit opotřebovaná kolečka automatického podavače. Zpětně tak můžeme výběr skeneru hodnotit jako velice úspěšný.
Od možností skeneru se zpětně odvíjel postup samotného skenování kartotéčních lístků. Nejprve bylo třeba lístky připravit pro mechanické skenování, což obnášelo především odstranění všech sponek a svorek, které by mohly poškodit skener, a – trochu nečekaně – i důkladné vyluxování skenovaného šuplíku, neb se záhy ukázalo, že skener se poměrně rychle zanáší drobným prachem z lístků. Paralelně probíhala i indexace kartotéky na dílčí části, protože šuplík o 2-3 tisících lístků se nám pro tak rozsáhlý katalog zdál relativně velkou členící jednotkou. Nakonec jsme sáhli k dělení katalogu na skupiny po cca 200-300 lístcích, díky němuž je výsledně badateli nabídnuto hned zpočátku práce s katalogem poměrně dosti detailní základní členění.
Další zpracování dat se už odvíjelo i od podoby budoucího softwarového řešení, které mělo nad celou kartotékou stát. Chtěli jsme už od počátku připravit takový systém, který by umožňoval využít OCR přepisů lístků a nabídnout nad nimi fulltextové vyhledávání, což by možnosti využití kartotéky zmnohonásobilo. S touto perspektivou se nám proces zpracování skenovaných lístků rozdělil na několik dílčích fází.
2.2. Softwarové zpracování skenovaných lístků
V první jsme řešili samotné základní zpracování seskenovaných dat. Zde bylo třeba především rozhodnout, v jakém grafickém formátu a v jaké kvalitě budeme jednotlivé obrázky skenovat. Lístky měly být jednak dobře čitelné pro uživatele na webu, ale zároveň i pro OCR program, což při jejich značné heterogennosti (lístky psané rukou, na stroji, tištěné z počítače; lístky s řadou ručních vpisků a škrtů kvůli později doplněným údajům; lístky různého stáří i různé barvy použitého inkoustu atp. atd.) vyžádalo vyzkoušet různé dostupné varianty. Po zkušebním testování kombinací jednotlivých grafických formátů, barevných kombinací a kvality rozlišení nám jako nejstabilnější formát s nejlepší kvalitou výsledků následného OCR přepisu vyšel barevný tiff v nejvyšším možném rozlišení 600*600 dpi, byť pro některé typy lístků vycházely lépe kombinace jiné. Tytéž kombinace však nebyly schopné u jiného typu lístků přečíst vůbec nic. U takto heterogenního materiálu se nám tak dle testování zdálo nejlepší zvolit co nejvyšší kvalitu zdrojových obrázků i za cenu zvýšených nároků na jejich archivaci.
Další problémy se staly už přímou součástí vlastního softwarového řešení, které pro nás připravila firma inSophy. Jednak bylo potřeba vyřešit vzájemné spojení všech částí „víceobrázkových“ lístků, tj. lístků oboustranných a vícestránkových, a především pak vyřešit problém automatického třídění prázdných stran. Tuto funkci nabízel i použitý skener, ale jednak by to zvyšovalo časové nároky na zpracování dat, druhak nebylo při použití algoritmu ve skeneru možné výsledně spojit dohromady víceobrázkové lístky. Zároveň pak bylo potřeba zvolit i vhodné pojmenování názvů souborů.
Z možných řešení jsme nakonec postupovali následovně: lístek byl v této fázi zpracování vždy chápán jako složenina dvou obrázků (rubu a líce). Pakliže bylo pro jeden záznam použito lístků více, bylo třeba k jejich základnímu pojmenování přidat smluvený příznak. Toto ruční doplňování se však týkalo cca 1 promile zpracovávaných lístků a práci zásadně nezdržovalo (i tak však šlo o cca 1500 lístků). Na základě tohoto přidaného příznaku pak systém při následném zpracování automaticky rozpoznal, zda má před sebou lístek o jednom, dvou či třeba sedmi lístcích.
Tuto operaci již prováděla první softwarová utilita, která krom spojování vícelístkových lístků řešila i přejmenování lístků na jednoznačně identifikovatelný tvar. Vstupní data totiž byla označována průběžným číslováním, což pak velmi usnadňovalo počáteční automatické kontroly integrity dat (souvislost vstupní číselné řady, zda je vstupní počet obrázků sudý, zda byly správně zapsány příznaky u vícelístkových lístků atp.). Po zpracování první utilitou byla přejmenována na tvar jméno skupiny+pořadí lístku ve skupině+pořadí strany daného lístku, což se posléze ukázalo jako výhodné pro vlastní zpracování ve webovém prohlížecím systému.
Asi nejdůležitějším úkolem, který první softwarová utilita řešila, byla automatická detekce prázdných stran lístku. Toto se dělo vždy jen u sudých stran lístků, a to na základě několika kritérií, zejména pak výpočtu kolik procent bodů na lístku se odchyluje od mediánu jeho barevné hodnoty o více, než byl přednastavený interval. I zde bylo zpočátku třeba experimentovat, nicméně zdařilo se nám vyladit nastavení tak, že systém lístky detekoval s úspěšností cca 98-99 %, a pakliže se mýlil, tak vždy označil plný lístek jako prázdný, nikoli obráceně.
2. 3. OCR rekognoskace a export dat do webové aplikace
Výsledně jsme tedy po zpracování seskenovaných obrázků první utilitou dostali přejmenované soubory, připravené pro zařazení do webové prezentační databáze, rozdělené na soubory s textem a bez něj (ty byly z dalšího zpracování vyřazeny). V tomto momentě následovala druhá manuální kontrola skenovaných obrázků, která korigovala případné chyby v detekci prázdných stran. Tato část byla pro zpracovávající obsluhu skeneru asi nejsložitější na pozornost a časově nejnáročnější, nikoliv však nějak zásadně. Zpětně jsme tuto manuální kontrolu docenili ještě ze dvou dalších důvodů: zaprvé při ní bylo možno obrátit případné otočené lístky a zadruhé bylo možno odstranit makulatury, které byly občas při excerpci používány a které samozřejmě nebylo možné vytřídit automatickým algoritmem.
U takto prověřených lístků jsme tak věděli, že máme jen ty lístky, které nesou relevantní textovou informaci, jsou stranově náležitě otočené a v případě oboustranných či vícelístkových lístků je zajištěno vzájemné spojení jejich jednotlivých částí. V tomto momentě bylo možno lístky zpracovat pomocí OCR. Zde jsme používali běžně dostupný komerční produkt Fine Reader, který nám umožnil pojmenovat vzniklé textové přepisy stejně jako jejich obrázkové předlohy, což pak usnadnilo jejich vzájemnou identifikaci ve webové bázi. Vzhledem k jazykové heterogenitě materiálu jsme při OCR rekognoskaci nepoužívali žádných automatických jazykových vylepšení a podobných funkcí. I když možnosti OCR dosti omezovaly ruční vpisky do strojopisných lístků, dosáhli jsme i zde nad očekávání dobrých výsledků. Přestože pro OCR rekognoskaci samozřejmě nebyly použitelné ručně psané lístky a většinou ani ne lístky psané přes průklepový papír, bylo pro případné vyhledávání v textových přepisech zpřístupněno cca 75 % kartotéky, samozřejmě v rozdílné kvalitě odpovídající vstupním dokumentům.

Syntetický obrázek excerpčního lístku
Oskenované obrázky obohacené o jejich OCR přepisy byly následně zpracovány druhou softwarovou utilitou. Její úkol byl oproti první relativně jednoduchý: spárovat obrázkové podoby lístku s jejich textovými podobami do jedné databázové jednotky a tu migrovat do webové databáze. V tento moment byly zároveň grafické soubory konvertovány do formátu png na únosnou velikost, která by zajišťovala jejich snadné a rychlé načítání na webu. Původní soubory ve formátu tiff byly následně komprimovány a ve dvou exemplářích archivovány pro případ nenadálé události.
Všechny výše popsané procesy běžely po celou dobu řešení projektu paralelně na dvou výkonných stolních počítačích, které byly při automatickém dávkovém zpracování dat vytěžovány v pracovních dnech prakticky celých 24 hodin a následně i valnou část víkendu. Při výsledném počtu cca 1,6 milionu oskenovaných lístků bylo takto za celou dobu řešení projektu zpracováno přes 80 TB dat, komprimované zálohy objímají necelých 20 TB. Základní jednotkou pro zpracování se stal jeden 2 TB harddisk a o průběhu zpracování dat a jeho kontrolách byly systematicky pořizovány průběžné protokoly (výpisy dat v jednotlivých fázích zpracování, protokoly o pohybu dat v obou softwarových aplikacích atp.).
2. 4. Webová aplikace pro prohlížení dat
Samostatnou kapitolou se pak stalo vlastní softwarové řešení webové aplikace pro prezentaci pořízených dat. I to se nám rozdělilo do několika dílčích, byť samozřejmě vzájemně provázaných a komunikujících částí.
Základní rovinu představovalo samostatné procházení původního lístkového katalogu. Zde svým způsobem nebylo nutné vytvářet nějaké speciální řešení, neboť procházení kartotéky by mělo z logických důvodů co nejvíce kopírovat podobu původního lístkového katalogu. Namísto jednotlivých šuplíků jsme však jako jednotlivé částí zvolili pro přehlednost jednotky menší, tj. skupiny o cca 200-300 lístcích, jak už bylo popsáno výše. Základní procházení katalogu se nám podařilo obohatit o několik dalších funkcionalit, především o možnost zvolit si formát prezentovaných obrázků. Uživatel je tak může vidět v úplnosti, nebo jen v podobě zmenšených náhledů pro rychlejší postup katalogem, v případě zájmu může volit tabulkové zobrazení základních údajů o lístcích či procházení v OCR přepisech. Zároveň může zvolit procházení v uměle generovaných kartičkách, vznikajících na základě uživatelských přepisů lístků, o nichž se ještě zmínim později. Volitelný je i počet zobrazených lístků na stránku a už ze základního procházení katalogu je možné exportovat vybrané lístky do tzv. schránky, která bude ještě přiblížena v dalším.
Náhled do administrace systému RETROBI
Další skupina funkcionalit je navázána na zobrazení jednotlivého lístku jako základní položky databáze: vedle přehledu všech hodnot, které jsou v bázi na lístek napojeny, jde především o možnosti uživatelské či administrátorské editace toho kterého lístku. Registrovaným uživatelům je otevřena možnost korigovat a do databáze ukládat původní OCR přepisy lístků s nadstavbovou možností segmentace. Segmentací je myšleno hrubé rozdělení lístku na základní části: záhlaví, autorské a názvové údaje, bibliografickou citaci a anotaci s případným věcným popisem. V systému RETROBI segmentace funguje na základě vložení znaku | na hranice příslušných segmentů v daném přepisu: speciální algoritmus pak vyhodnotí, zda uživatelem provedená segmentace odpovídá některé z variant možného pořadí jednotlivých segmentů, které byly v kartotéce používány, a původní OCR přepis lístku na tyto dílčí části rovnou rozdělí. Druhou možností editace dat na lístku je položkový rozpis. Uživatelé s pokročilými právy mají k dispozici konfigurovatelný formulář, v němž mohou vyplnit jednotlivé konkrétní databázové hodnoty (autor, název, hodnoty věcného popisu atp.). Momentem uložení editovaných textů do systému se tyto okamžitě stávají přístupné pro vyhledávání v textových množinách.
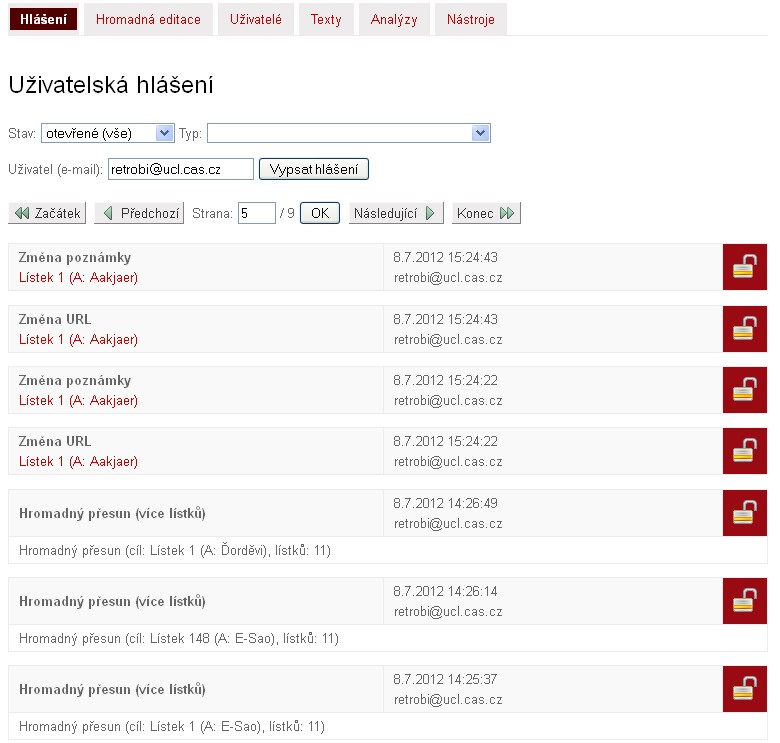
Vedle editačních funkcionalit je pak u každého lístku k dispozici systém administračních hlášení, jehož prostřednictvím může uživatel nahlásit administrátorům jakoukoli chybu uvnitř systému. Dále pak si každý registrovaný uživatel může k jednotlivým lístkům ukládat své vlastní komentáře. Pro administrátory jsou pak u jednotlivého lístku k dispozici rozličné nástroje pro správu jednotlivých lístků – pro přesuny, mazání, vkládání nových obrázků atp.
Velkou, ne-li největší předností systému RETROBI, je možnost vyhledávání v textových přepisech jednotlivých lístků. Jako základní úroveň zde slouží fulltextové vyhledávání v OCR přepisech lístků, avšak zároveň jsou k dispozici možnosti pro nejrůznější specifikaci dotazu (omezení na konkrétní část/i katalogu či omezení na jednotlivé segmenty či přímo jednotlivé databázové položky, které je samozřejmě odvislé od množství přepsaných lístků). Výsledky vyhledávání lze exportovat do schránky a na množinu lístků ve schránce lze dotaz i omezit. Pro vyhledávání byl do systému implementován výkonný vyhledávací engine Lucene, který jeho možnosti dále rozšiřuje. Umožňuje mimo jiné klást kombinované dotazy pomocí základních logických operátorů, pracuje s hledáním na základě podobnosti, vzdálenosti slov od sebe atp. Jeho největší předností však bezesporu je možnost využití tzv. divokých karet, tj. speciálních znaků, které na daném místě ve vyhledávaném řetězci suplují jakýkoli jiný znak či řadu znaků. Možnosti vyhledávání v textových datech tak značnou měrou rozšiřují možnosti využití kartotéky. I když je vyhledávání funkční nad cca 75 % kartotéčních lístků, a to ještě v nestejné kvalitě, představuje pro další práci s daty velmi silný nástroj, který umožňuje nalézt lístky i dle jiných kritérií, než dle jakých jsou řazeny jednotlivé části kartotéky (např. dle konkrétního titulu periodika, dle roku vydání zdrojového dokumentu, jazyka originálu u překladových textů atp.). S prvními výsledky, které nám systém nabízí, jsme více než spokojeni a našeho původního rozhodnutí využít při konstrukci systému OCR přepisů, které celý proces zpracování značně zkomplikovalo, rozhodně zpětně nelitujeme. Do budoucna se nám tu otevírá prostor pro automatickou hromadnou indexaci definovaných množin lístků o vybrané databázové hodnoty.
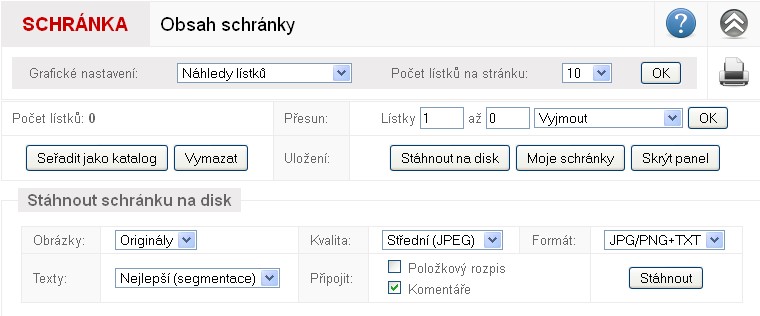
Velmi důležitou komponentou systému je tzv. schránka
Pomocí funkcionality nazvané schránka si může uživatel shromažďovat, třídit a ze systému exportovat libovolné rešerše. Schránka je přístupná jak ze základního procházení katalogu, tak z vyhledávání. Uživatel v ní může přesouvat nejen jednotlivé lístky, ale i celé jejich sekvence. V případě zájmu si může své schránky v systému uložit a po čase se k nim vrátit. Zřejmě nejvděčnější součástí schránky je možnost exportu dat. Export dat je koncipován jako velmi konfigurovatelný: uživatel si může vybírat různé kvality i formáty exportovaných obrázků, stejně jako je mu umožněno specifikovat i vybraná textová data (přepisy, položkové rozpisy, komentáře atp.). Jednotlivé lístky jsou ze systému exportovatelné buď jako jednotlivé soubory, nebo jako jeden hromadný rtf soubor, který si pak daný uživatel může dále libovolně zpracovávat.
Již několikrát byla zmíněna funkce registrace. Ta je v systému koncipována jako nepovinná a neregistrovaný uživatel získá možnost přístupu ke všem datům, která jsou v systému obsažena. Registrovaný uživatel jako bonus získává přístup k editaci textových dat a možnost ukládat si v systému své schránky. Větší rozsah uživatelských práv získává editor: jemu je k dispozici i formulář pro položkový rozpis a některé jednodušší administrátorské funkce. Přístup k nastavení základních systémových parametrů aplikace má samozřejmě jen administrátor celého systému.
Administrace systému zůstává běžnému uživateli nedostupná, přesto i zde nalezneme několik zajímavých funkčních celků. Již byl zmiňován systém pro administraci uživatelských hlášení, kde administrátor může jednotlivá hlášení filtrovat dle data, typu či uživatele a dále přímo odsud případně provádět korekce v bázi. Samozřejmostí je i konfigurovatelný formulář pro správu uživatelských účtů, kde administrátor může měnit role jednotlivých uživatelů, nastavovat jim počty schránek či maximální počet lístků v nich. K dispozici jsou i komponenty pro statistické zpracování dat i kontrolu integrity dat v bázi kvůli možným přesunům v ní. Všechny události v systému jsou konečně logovány do csv souborů pro případ komplikací při chodu systému.
Nejzajímavější součást administrace tvoří zřejmě nástroje pro hromadnou editaci. Jejich prostřednictvím je možno libovolné množině lístků hromadně vyplnit či změnit jakoukoli hodnotu položkového rozpisu. Protože databázová struktura není úplně triviální (opakovatelná pole, pole s podpoli atp.), byla sem integrována řada kontrolních nástrojů, která sleduje, zda dané pole u konkrétního lístku je vyplněno či není, popř. není-li již vyplněno totožnou hodnotou. Při pokusném testování báze na podzim loňského roku se nám prostřednictvím tohoto nástroje podařilo doplnit více než polovině lístků (cca 600 tis.) hodnoty pro rok vydání, které jsou v přepisu identifikovatelné nejsnáze, a to byly doplňovány jen hodnoty z let 1918-1945. Věříme tak, že do budoucna bude možné takto databázi detailněji naindexovat a zpřístupnit pro složitější vyhledávací dotazy a zároveň nabídnout i relevantnější výsledky.
3. Závěr a náhled do budoucnosti
Momentálně je před námi dokončení skenování kartotéky. Ke konci června 2012 bylo v systému k dispozici 1 566 835 lístků. Je tak před námi ještě digitalizace dešifrátové části o cca 20 000 lístků, odkládaná kvůli souběžnému archivnímu výzkumu, který bychom rádi ještě promítli do stávajících dat. Seskenováno nakonec nebylo ani cca 90 000 lístků dostupných v databázové podobě jako databáze RET, které jsou k dispozici v plnohodnotné databázové podobě.
Projekt RETROBI však momentálně lze považovat za úspěšně dokončený. Veřejnosti je dostupný na adrese http://retrobi.ucl.cas.cz/retrobi/ . Do budoucna plánujeme jeho další rozvoj především ve dvou směrech. Naznačeny byly již možnosti hromadné editace a snad se nám zdaří i motivovat uživatele k přepisům a korekcím stávajících dat, čímž by se celý projekt mohl dále rozvíjet jakýmsi samopohybem. Rádi bychom pak software v dohledné době upravili i pro prezentaci dalších lístkových kartoték, které jsou v ÚČL k dispozici.