Zpráva z workshopu Big Clean v Národní technické knihovně
V sobotu 19.3.2011 uspořádala Národní technická knihovna společně se Studii nových médií Filozofické fakulty Univerzity Karlovy workshop nazvaný Big Clean, který byl věnován praktickému čištění dat veřejné správy. Big Clean probíhal souběžně v Praze a ve finském městě Jyväskylä jako mezinárodní událost pod záštitou organizace Open Knowledge Foundation. Během dne se nabízely dva paralelně probíhající programy. Jeden byl vždy více zaměřen na aktivní zapojení účastníků, zatímco v rámci druhého se probíhaly přednášky. Jedna část programu byla věnována samotnému získávání a čištění dat, a proto vyžadovala spíše technicky zdatné účastníky. Naproti tomu v druhé části byly představeny relativně snadno ovladatelné nástroje pro užití již existujících dat.
Na začátku workshopu byli jeho účastníci seznámeni se záměrem, s nímž byl Big Clean uspořádán. Hlavní myšlenkou workshopu bylo naučit zúčastněné na příkladech, jak si vzít nestrukturovaná data, která jsou na webových stránkách veřejných institucí, a vyrobit z nich kvalitní, čistá a strukturovaná data. Ta lze poté zveřejnit tak, aby je ostatní mohli rovnou použít. Díky tomu nemusejí procházet jejich převodem do podoby vhodné pro automatizované zpracování a následné uplatnění v různých nástrojích. Šlo tedy o odstranění bariéry pro další uživatele dat, pro zjednodušení jejich cesty k surovým, strukturovaným datům veřejné sféry. Právě ta jsou často k mání pouze v podobě webových stránek, které jsou sice srozumitelné lidem, ale pokud jsou údaje v nich obsažené potřeba v různých nástrojích nebo aplikacích, je zapotřebí je nejprve upravit a převést do strukturovaného formátu.

Zahájení workshopu v Ballingově sále
Program celého dne vytvářel cyklus: od získávání a čištění dat, přes jejich analýzy až k uplatnění dat v žurnalistice. Šlo o to nejprve získat z webových stránek veřejného sektoru strukturovaná data, zpracovat je a dostat z nich příběhy. Fakta, o nichž data vypovídají, se mohou stát základem třeba pro novinový článek. Cyklus byl demonstrován na příkladu dat o znečištění ovzduší v České republice, která zveřejňuje Český hydrometeorologický ústav. Přednášející ukázali, jak lze tato data vydestilovat z webových stránek, na nichž se nacházejí, jak na nich můžeme předvést neúplnost anebo jak informace z nich získané lze promítnout do mapy.
Po krátkém úvodu byli přítomní postaveni před nelehkou volbu: vybrat si ze dvou paralelně probíhajících programů. Zatímco někteří dali přednost předvedení praktických nástrojů pro práci s daty, druzí se vydali diskutovat o stavu otevřeného zpřístupňování dat vytvářených veřejnými organizacemi v České republice.
V rámci prvního přednáškového bloku představil Jindřich Mynarz nástroj ScraperWiki pro kolaborativní vytváření screen-scraperů a mluvil o tom, jak vypadá zodpovědné scrapování, které je ke zpracovávaným webovým stránkám šetrné. Screen-scrapery jsou programy pro převádění webových stránek (obvykle HTML) na strukturovaná data (např. CSV, XML apod.). Vytváření programů právě tohoto typu bylo náplní praktické odpolední sekce.
Jakub Nešetřil účastníky seznámil s nástrojem Google Refine. Ten nabízí mocný, ale zároveň uživatelsky přívětivý nástroj pro práci s tabulkovými daty, umožňující data různými metodami čistit (např. od překlepů nebo duplicit).

Štefan Urbánek přednášel o kvalitě dat
Štefan Urbánek mluvil o sledování kvality dat a kromě vymezení samotného konceptu kvality dat se zmínil o možnostech jeho měření a faktorech, které jej ovlivňují, jako je třeba jejich úplnost. Stručně uvedl svůj projekt nástroje pro analytické zpracování dat nazvaný Brewery. Jako příklad z praxe ukázal slovenský Věstník veřejných zakázek, na jehož zpracování se podílel.
Během dopoledne současně probíhala diskuse o otevřených datech ve veřejné správě vedená Martinem Nečaským z Matematicko-fyzikální fakulty Univerzity Karlovy. Ten vystoupil jako zástupce skupiny OpenData.cz, české iniciativy pro otevřenou infrastrukturu dat veřejné správy.

Martin Nečaský na diskusi o otevřených datech ve veřejné správě

Diskuse o otevřených datech ve veřejné správě
Odpolední hackování pod vedením Jindřicha Mynarze a Štefana Urbánka začalo videem představujícím ScraperWiki, tentokrát z pozice jeho vývojáře Francise Irvinga, jenž krátkou přednášku dříve během dne přednesl pro účastníky finského Big Cleanu. Následně se jeho účastníci rozdělili do menších skupin podle programovacích jazyků, které ovládali, a to z těch, které jsou podporovány ScraperWiki (mezi nimi je Python, Ruby a PHP). Každá skupinka si vzala na starosti převedení některých vytipovaných dat, mezi něž patřil například seznam nahlášených veřejných sbírek nebo seznam insolvenčních správců.

Odpolední hackování
Odpolední program přednášek a praktických ukázek nástrojů se věnoval způsobům, jimiž lze strukturovaná data využít, např. v novinářské praxi. Jednak šlo o to, jak data předzpracovat, filtrovat nebo kombinovat, a pak o to, jakým způsobem je prezentovat, např. formou vizualizace nebo skrze příběh.
Josef Šlerka načrtl způsoby, jak lze vytvořit vlastní malý monitoring médií za pomoci nástrojů jako je Yahoo! Pipes, který umožňuje snadno kombinovat různé webové zdroje, nebo Yahoo! Query Language, pomocí něhož se lze dotazovat datových zdrojů a webových stránek, jakoby měly API (Application Programming Interface - rozhraní pro přístup pomocí programů). Ukázal také možnosti, jaké nabízí aplikace Google Fusion Tables. Ta umožňuje zpracovávat poměrně rozsáhlé objemy tabulkových dat s tím, že poskytuje funkce pro jejich analýzu a vytváření náhledů, např. pomocí projekce do mapy. Nakonec Josef Šlerka seznámil posluchače s tím, jak lze aplikovat metody social network analysis na data o vazbách ve veřejném sektoru, a to na příkladu hlasování zastupitelů z pražského magistrátu.
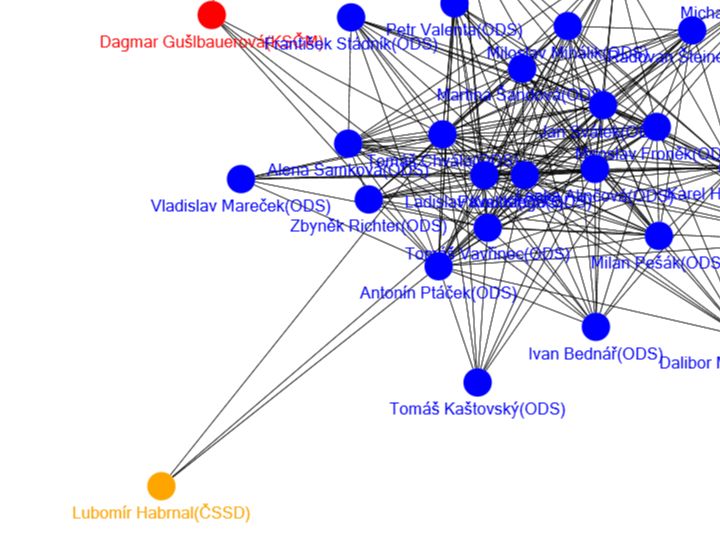
Vizualizace založená na hlasování pražských zastupitelů od Josefa Šlerky

Jan Boček hovořil o datové žurnalistice
Následovala vystoupení dvou publicistů, konkrétně Adama Javůrka a Jana Bočka. Představili způsoby, jimiž mohou být surová, strukturovaná data uplatněna v žurnalistice. Jednou z hlavních oblastí v novinářství, pro něž jsou data nezbytná, jsou informační vizualizace. Ty prezentují informace skryté v datech v přístupné, obrazové podobě, např. jako projekci údajů na mapu nebo v grafu. Rolí novináře je pak pro čtenáře data správně interpretovat a prezentovat přístupnou formou. Adam Javůrek představil celou řadu úspěšných vizualizací, které dokázaly přitáhnout pozornost, a zmínil se o nástrojích, pomocí nichž si může každý zkusit podobná grafická znázornění dat vytvořit. Jan Boček promluvil o tom, jak se data v klasické žurnalistice ztrácejí vlivem toho, jak jsou transformována do článků. Naproti tomu žurnalistika založená na datech, objevující se například v novinách jako jsou New York Times nebo britský Guardian, dává čtenářům jak příběh ve formě článku, tak surová data. Kromě toho, jak se tato žurnalistika dělá a jak vypadá, představil Jan Boček jako její příklad projekt občanského sdružení Brnění mapující hazardní herny v Brně.
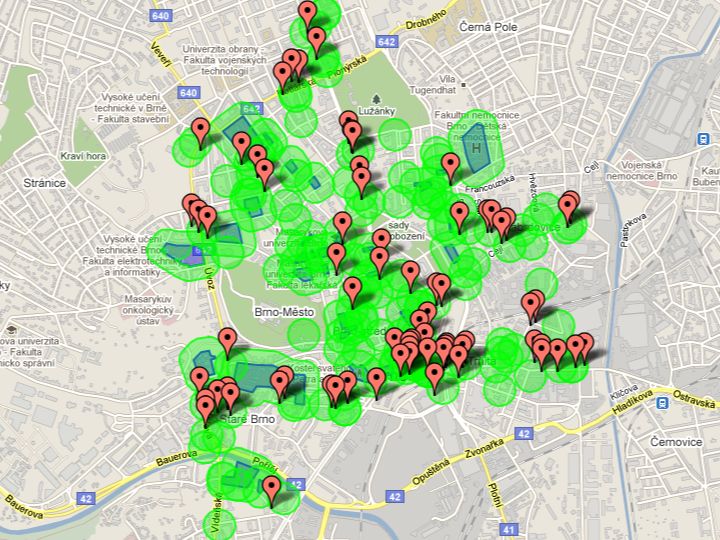
Mapa brněnských heren představená Janem Bočkem
Workshopu se zúčastnilo celkem 80 lidí, z čehož se přibližně 15 podílelo aktivně na screen-scrapování dat české veřejné správy v praxi v rámci odpoledního hackování. Bylo vytvořeno několik funkčních screen-scraperů zprostředkovávajících data z webů veřejné správy ve strukturované podobě. Screen-scrapery samotné jsou pod tagem bigclean volně dostupné na ScraperWiki.
Podrobné informace o workshopu včetně promítaných slidů přednášejících, lze nalézt na jeho webové stránce. Výstupy účastníků workshopu, zahrnující například jejich poznámky nebo vytipovaná data, jsou k dispozici ve veřejně přístupných, sdílených dokumentech Google Docs, a to jak pro dopolední diskusi o otevřených datech ve veřejné správě, tak pro odpolední hackování. Odkazy na informační vizualizace, které zmiňoval během své přednášky Adam Javůrek, jsou k nalezení rovněž ve sdíleném dokumentu.
Kromě rozhovorů účastníků probíhala komunikace v elektronickém prostředí. Bylo to na IRC kanálu Open Knowledge Foundation, kde byli k dispozici tvůrci ScraperWiki, odpovídající na otázky a připraveni pomoci s řešením problémů, s nimiž se zúčastnění setkali. Konverzace mezi účastníky probíhala také prostřednictvím zpráv na Twitteru pod hash-tagem #bigcleancz nebo skrze účet pořadatelů @BigCleanCZ. Díky specifickému zaměření workshopu a širokému rozptylu zastoupených oblastí si během něj měly šanci spolu povídat skupiny, které se spolu často nesetkávají, jako třeba vývojáři aplikací a zástupci médií.
Jedním z výstupů workshopu je vizualizace údajů o evidovaných veřejných sbírkách v České republice. Je založená na datech, která byla zpracována a převedena během odpoledního hackování jedním z účastníků. Její první verzi předvedl na konci dne Josef Šlerka. Na mapě ukazovala rozložení míst, kde byly veřejné sbírky vypsány, a objevily se na ní dobře rozeznatelné shluky ve třech oblastech. Na první pohled nebylo zřejmé, z jakého důvodu k této koncentraci došlo, ale poté Josef Šlerka stejná data ukázal na časové ose. Když se dostal k popiskům přiřazeným ke sbírkám náležejícím ke zmiňovaným shlukům, ukázalo se, že všechny měly stejnou příčinu - povodně.
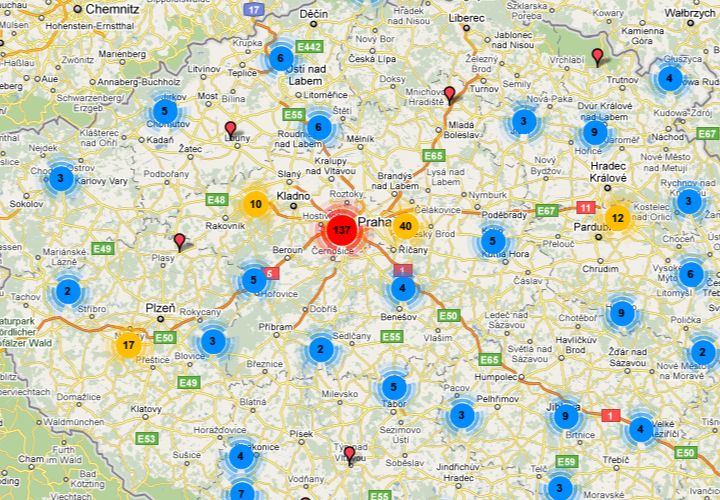
Mapa probíhajících veřejných sbírek
Stejně tak, jako z údajů na webových stránkách seznamu veřejných sbírek není zjevné, že největší počet sbírek byl vyhlášen pro oblasti zasažené povodněmi, nemusí být na první pohled jasné, proč data veřejné správy potřebujeme. Často nemusíme tušit, k čemu nám strukturovaná data mohou být užitečná. Big Clean proto na příkladech předvedl, proč by data veřejné správy měla být občanům volně k dispozici ve strukturované podobě, a dal zúčastněným nahlédnout několik způsobů, jimiž mohou být taková data uplatněna.