MUFIN: buďte v obraze!
Kolikrát za svůj život jste při práci nebo zábavě použili Google či jiný vyhledávač, abyste našli nějakou informaci? Pravděpodobně tak často, že už si práci bez nich téměř neumíte představit - jedná se o neocenitelné pomocníky při vyhledávání v textových datech. Ale nepřeberné množství dat, které máme na dosah ruky, se už dávno neskládá jen z textu, obsahuje i obrázky, videa, zvuky, ale také třeba sekvence DNA. Jak rozumně vyhledávat zde?
Leckterého čtenáře asi napadne, že některé vyhledávače přece umí pracovat i s obrázky. Ve skutečnosti ale to, co často považujeme za vyhledávání v obrázcích, je jen vyhledávání v jejich textových popiscích. To samozřejmě není totéž – pokud k fotografii kopretiny někdo napíše, že je to bodlák, bohužel ji na dotaz kopretina nenajdete. Přitom to ale může být právě ta fotografie, kterou hledáte. Jak to tedy počítači říci? Řešení, které představuje tento článek, umožňuje formulovat dotazy pomocí vzoru, tedy například jiné fotografie či kresby.
Od uspořádaných souborů k metrickému prostoru
Formulování dotazů nad složitějšími daty pomocí vzorů se podstatně liší od klasického vyhledávání, jaké známe například z databází. Základním rozdílem, kvůli kterému není možné použít běžné databázové techniky, je skutečnost, že domény různých multimediálních typů nejsou lineárně uspořadatelné. Jinými slovy není možné seřadit všechny objekty, například obrázky, do řady tak, aby ke každému obrázku byly vedle něj ty nejpodobnější. Pak ale nemůžeme použít běžné indexovací techniky, protože ty umí hledat pouze v takto uspořádaných datech. Je tedy třeba hledat nové přístupy, které by vyhovovaly i složitějším doménám.
Vhodným řešením uvedeného problému se zdá být podobnostní vyhledávání, které je už řadu let významným výzkumným tématem. Podobnostní přístup pracuje s daty na základě velmi obecného konceptu metrického prostoru, kde kromě objektů samotných musí být definována i distanční funkce, která vyjadřuje vzdálenost mezi objekty. Pro každé dva objekty z domény tedy umíme určit tuto vzdálenost, která intuitivně odpovídá podobnosti, či spíše nepodobnosti – nulová vzdálenost je identita, čím vzdálenější objekty, tím méně jsou si podobné. V případě obrázků můžeme jako vzdálenost uvažovat například nepodobnost barev, viz obrázek 1.

Obrázek 1: Dotazování podle vzoru – vzor a odpověď pro podobnost podle barev (obrázky v odpovědi jsou seřazeny podle vzdálenosti od vzoru)
Způsob výpočtu vzdálenosti, struktura ani vlastnosti objektů nejsou pro podobnostní vyhledávání podstatné, s objekty se zachází jako s černou skříňkou. Díky tomu je podobnostní vyhledávání velmi obecným a široce použitelným přístupem. Vlastní vyhledávání pak spočívá v nalezení objektu (případně množiny objektů) s nejmenší vzdáleností k danému vzoru, případně nalezení objektů se vzdáleností menší než daná mez. Pro efektivní vyhledávání se používají specializované indexové struktury. Pro detailnější seznámení s principy podobnostního vyhledávání je možno nahlédnout např. do knihy [1].
MUFIN: MUlti-Feature Indexing Network
Cílem projektu MUFIN, který je vyvíjen na Fakultě informatiky Masarykovy univerzity, je umožnit vyhledávání v libovolných datech, která splňují požadavky metrického prostoru. Pro každou takovou datovou doménu a distanční funkci je možné vybudovat indexovou strukturu, která umožní efektivní podobnostní vyhledávání nad daty z domény vzhledem k dané vzdálenosti. První aplikací, na které se schopnosti MUFINu v praxi testují, je vyhledávání mezi obrázky získanými z webové databáze Flickr. Na této aplikaci si blíže ukážeme, jak MUFIN funguje.
Jak již bylo zmíněno, pro zvolenou datovou množinu (v našem případě tedy kolekci 50 000 000 obrázků) a vzdálenostní funkci je vytvořena indexová struktura. Poslední dvě písmena v názvu vyhledávače jsou zkratkou slov Indexing Network a signalizují, že indexování a vyhledávání se odehrává v síťovém prostředí. MUFIN využívá distribuovanou peer-to-peer architekturu, díky které je zaručena škálovatelnost systému při zachování rychlé odezvy. Data jsou tedy rovnoměrně rozdělena mezi několika vzájemně propojených počítačů (uzly), jejichž počet se může zvyšovat či snižovat podle potřeby. Kterýkoli z uzlů sítě může být uživatelem požádán o spuštění dotazu, jehož zpracování se odehrává v několika krocích. Oslovený uzel na základě svých znalostí o organizaci dat v síti nejprve vyhodnotí, které uzly mohou obsahovat relevantní data, následně v nich paralelně spustí vyhledávání, získá výsledky, spojí je, setřídí a prezentuje uživateli. Použití síťového prostředí tak umožňuje zvládání velkého objemu dat a rychlé vyhodnocení dotazu díky paralelnímu zpracování na více strojích.
Vyhledávání podle jedné vzdálenosti však není to jediné, co MUFIN umí. K jedné datové množině je možné nadefinovat několik různých distančních funkcí a při vyhledávání jednotlivé vzdálenosti kombinovat. Tato vlastnost je velmi užitečná - je totiž v podstatě nemožné najít univerzální vzoreček pro to, co my lidé chápeme jako podobnost. Snazší je definovat několik dílčích vzdáleností, u obrázků například podobnost podle barev či tvarů, a z těch pak skládat výslednou celkovou podobnost, která může být různá pro různé uživatele (někoho zajímá spíš tvar květiny, někoho barva) nebo situace (míč budu hledat spíše podle tvaru, louku podle barvy). Proto MUFIN umožňuje indexovat objekty podle několika různých vlastností (a k nim příslušejících vzdáleností). Pro každou tuto dílčí vzdálenost je definován jeden index a při samotném vyhledávání pak mohou být dílčí výsledky kombinovány podle preferencí uživatele. Systém tedy umožňuje vyhledávání podle více vlastností (Multi-Feature). Takové vyhledávání ovšem vyžaduje použití složitějších algoritmů a je časově náročnější.
V současnosti používáme pro vyhledávání v obrázcích pět různých deskriptorů podle standardu MPEG-7, z nichž dva popisují tvary a tři barvy obrázku. Celková vzdálenost mezi dvěma obrázky je počítána jako vážená suma těchto částečných vzdáleností, jejíž koeficienty byly zvoleny na základě rozsáhlých experimentů. Pro urychlení vyhledávání jsou objekty předem zaindexovány i podle této celkové vzdálenosti, aby se při vyhledávání nemuselo používat složitější procházení několika různých indexů. Indexy pro dílčí vzdálenosti se tedy použijí jen tehdy, když je změněno základní nastavení výpočtu celkové vzdálenosti.
Obrázkové vyhledávání v praxi
Dost již bylo teorie, nyní se pojďme podívat, jak MUFIN skutečně hledá. Od prosince minulého roku je veřejnosti k dispozici první zkušební verze vyhledávače, a to na adrese http://mufin.fi.muni.cz/imgsearch/. Zde si můžete sami vyzkoušet, jak vyhledávání funguje, k dispozici jsou dvě možnosti zadání dotazu – buď pomocí vzoru z databáze vyhledávače, nebo pomocí klíčových slov. Hledání pomocí klíčových slov funguje stejně jako u jiných vyhledávačů – prohledávají se popisky obrázků.
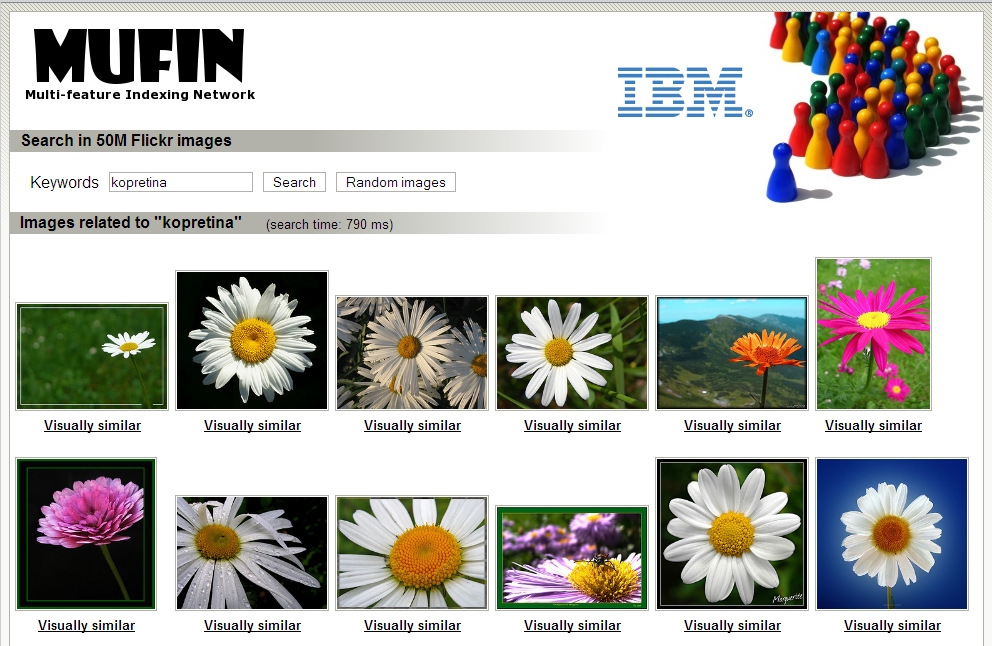

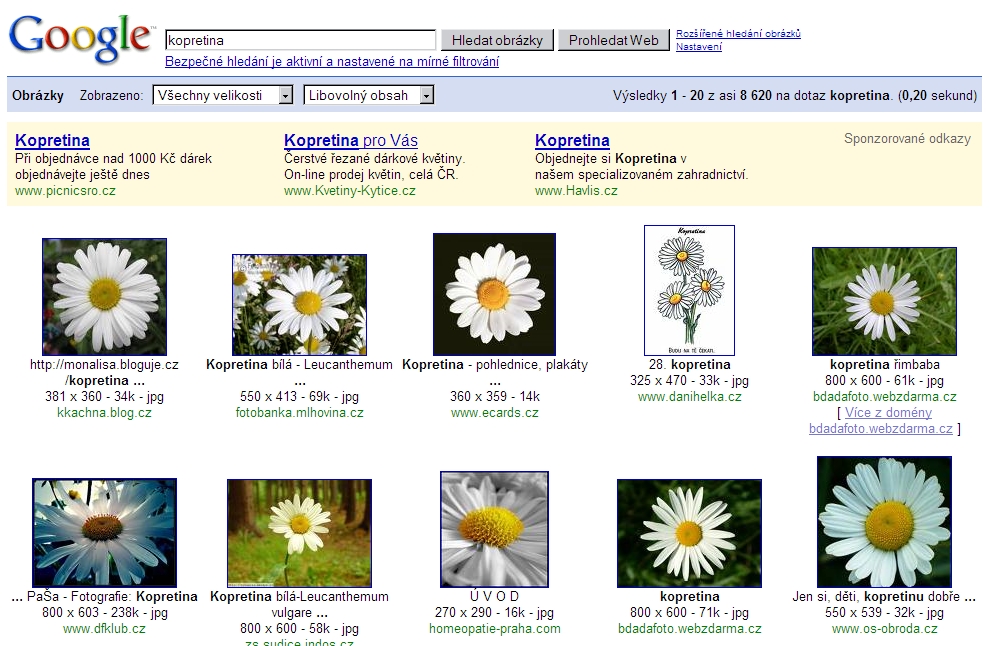
Obrázky 2-4: Hledání obrázku kopretiny – výsledky získané ve dvou krocích vyhledávání MUFIN a výsledky získané pomocí Googlu
Obrázky 2 a 3 ukazují, jak je možné tyto přístupy kombinovat – nejprve byl zadán textový dotaz, z jeho výsledků si uživatel zvolil obrázek, který nejlépe odpovídal jeho představám, a k němu nechal vyhledat podobné. Pro srovnání nabízíme také ukázku výsledku, který pro stejný dotaz vrátí Google (obrázek 4). Výsledky textového vyhledání jsou srovnatelné, ale chybí možnost dále hledání upřesnit výběrem preferovaného obrázku. U výsledku podobnostního hledání sice vidíme, že některé fotografie nezobrazují kopretinu, v jednom případě se dokonce nejedná ani o květinu, avšak obrázky jsou vizuálně podobné zadanému vzoru, tedy světlé květině na tmavém pozadí. Obrázky jsou řazeny podle vzdálenosti od vzoru, která je navíc vypsána nad každým náhledem. U prvního výsledku vidíme, že vzdálenost je nulová – našel se tedy samotný vzor.
Za dobu veřejného fungování MUFINu jsme si mohli ověřit, že architektura dobře zvládá požadavky reálného provozu. Systém běžně zpracovává 20 dotazů za sekundu při odezvě do půl sekundy. MUFIN je provozován na šesti serverech IBM, které jsme dostali jako cenu IBM Shared University Research. Servery jsou osazeny dvěma čtyřjádrovými procesory Intel Xeon 2GHz, mají 20GB RAM a diskové pole se šesti vysokorychlostními SAS disky.
A co dál
Zveřejněním první funkční verze vývoj MUFINu rozhodně nekončí. 50 milionů zaindexovaných obrázků zdaleka není cílová velikost, nyní pracujeme již s několika sty miliony a v plánu je vyzkoušet MUFIN i na miliardě. Proto je také potřeba stále optimalizovat indexovací metody tak, aby doba přístupu k datům byla co nejkratší. Jednou z rozvíjených metod je i přibližné vyhledávání, které nevrací úplně nejlepší výsledky (vzhledem k dané distanční funkci), najde však velmi dobré výsledky za podstatně kratší dobu. Tato výměna přesnosti za rychlost je výhodná tím spíše, že vnímání kvality výsledků podobnostního vyhledávání je subjektivní, takže uživatel může dokonce přibližné výsledky považovat za lepší než ty, které by systém vrátil jako přesné.
Zvídavý čtenář, který si hledání již vyzkoušel, si také jistě všiml, že ačkoli jsme v předchozí části mluvili o možnosti nastavit váhy jednotlivých deskriptorů MPEG-7 a ovlivnit tak výpočet celkové vzdálenosti, v uživatelském rozhraní příslušná volba chybí. Toto rozšířené vyhledávání je prozatím k dispozici pouze vývojářům, kteří se snaží o co nejefektivnější implementaci potřebných algoritmů – jak bylo zmíněno, vyhodnocování dotazu, který vyžaduje přístup do více indexů a kombinování mezivýsledků, je časově náročnější. Mezi dalšími plánovanými rozšířeními vyhledávání je také možnost dotazování podle více vzorů, vložení vlastního referenčního obrázku či kresby, rozeznávání a vyhledávání obličejů a mnohé další.
Na závěr připomeňme, že cílem MUFINu není jen zvládnutí obrázkového vyhledávání, ale umožnění podobnostního vyhledávání nad libovolnými daty. Můžeme proto přislíbit, že se připravují i další aplikace, například prohledávání videí.
- ZEZULA, P.; AMATO, G.; DOHNAL, V.; BATKO, M. Similarity Search: The Metric Space Approach. Springer-Verlag, 2006. Advances in Database Systems, vol. 32.