Google Books Ngram Viewer
Od 16. prosince 2010 může díky vizalizačnímu nástroji Google Books Ngram Viewer (dále jen Ngram) každý uživatel internetu prohledávat a porovnávat až pětislovné fráze, jež se používaly mezi lety 1500 až 2008 v tištěné knižní produkci. Nahlédnout lze do 5,2 milionu zdigitalizovaných knih (Google digitalizuje knihy od roku 2004), které obsahují 500 miliard slov. Celkový počet zpřístupněných knih odpovídá zhruba 4 % veškeré celosvětové tištěné produkce. Na vývoji Ngramu[1] spolupracoval Google s Harvardskou univerzitou, Massachusettským technologickým institutem a Encyklopedií Britannica.
Zpřístupněné knihy jsou rozděleny do následujících jazykových korpusů:
- americká angličtina – knihy, které byly publikovány v USA,
- britská angličtina – knihy, které byly publikovány ve Velké Británii,
- čínština (zjednodušená)
- angličtina – knihy nejsou filtrované podle předmětu – podobné jako „Google Million“ (viz níže)
- beletrie v angličtině
- anglický milion („Google Million“) - knihy v angličtině vydané mezi lety 1500 až 2008; z každého roku bylo vybráno maximálně 6 000 knih; do výběru se nedostali knihy, které byly pomocí OCR špatně rozpoznané, ani časopisy,
- francouzština – knihy původně ve francouzském jazyce,
- němčina – knihy původně v německém jazyce,
- hebrejština – knihy původně v hebrejštině,
- španělština – knihy původně ve španělštině,
- ruština – knihy původně v ruštině.
Vzhledem k tomu, že se jedná o vizualizační nástroj, všechny hledané výrazy se zobrazují do grafu, což umožňuje nejrůznější porovnávání výskytu jednotlivých slov či frází ve zvoleném časovém rozmezí nejen v rámci jednoho korpusu. Osa X zobrazuje zvolené časové období, na ose Y je uvedeno, kolik procent z celkového počtu „n-gramů“ hledaný termín zabírá. Navíc je do grafu promítnuta statistika, která ukazuje, kolikrát se ve zpřístupněném vzorku knih hledaný výraz v každém roce vyskytl. Díky širokému časovému rozmezí, několika jazykovým korpusům, velkému množství knih i slov lze sledovat výskyt až pětislovných frází nejen napříč stoletími, ale i napříč jazyky.
Ngram může být užitečný v mnoha vědních oborech – například lingvisté mohou zkoumat vývoj jazyka, změny v jazyce, frekvenci užívání slov, jejich postupné zastarávání, počátek výskytu slov nových, proměny významu atp.; historici jej mohou využít pro reflexi nejrůznější historických událostí a jejich interpretaci. Své uplatnění Ngram najde i mezi humanitními vědami či v sociologickém výzkumu. Může totiž sloužit nejen k porovnávání výskytu slov, ale například i ke zjišťování korelací mezi užitím konkrétního slova a nějakou událostí[2].
Při interpretaci zobrazených dat je však velmi důležitý kontext, především u víceznačných slov. Nemělo by se však zapomínat na to, že se význam jednotlivých slov v průběhu staletí proměňuje. Ngram totiž sice řekne, jak často se hledané slovo či fráze v knihách v daném období vyskytovalo, avšak nezodpoví otázku proč – ta je již na interpretaci hledajícího a na kontextu, který je možno získat přímo z knihy nebo ze znalosti historických událostí.
Díky napojení Ngramu na službu Google Books je možné nahlédnout do knih, které byly do Ngramu zařazeny a vyšly ve zvoleném období. Po rozkliknutí konkrétního titulu je zobrazena pasáž se slovy, které byly v Ngramu hledány. Uživatel tak může zkontrolovat správnost vyhledaného výrazu, technologie OCR, jejímž prostřednictvím jsou získávána data z tištěných knih, totiž není bezchybná. Zpřístupněná data jsou volně ke stažení. Uživatelé tak nad nimi mohou vytvářet vlastní vyhledávací nástroje.
Při zadávání dotazů je potřeba nezapomenout na to, že vyhledávání rozlišuje velikost písmen. Pokud chceme hledat přesný výraz, je potřeba jej zadat do uvozovek. Je však potřeba uvědomit si, že základem pro vyhledávání nejsou jen texty knih, ale i jejich přesná metadata, která umožňují nejen datovat výskyt hledaného výrazu, ale i určit autora knihy, místo jejího vydání a další informace. Tato metadata bohužel nemusí být vždy zcela přesná.
Přestože se do užšího výběru (zatím) nedostaly časopisy, blogy a další média ani další jazyky, je již v současné chvíli Google Books Ngram Viewer poměrně zajímavým nástrojem, který umožňuje nejen zkoumání jazyka a reflexi historických událostí v knižní tištěné produkci napříč pěti staletími.
Ukázky
V následujících několika ukázkách jsou pouze nastíněny možnosti užití Ngramu – porovnání korelace několika slov v rámci jednoho korpusu a výskytu jednoho slova v několika korpusech.
Na obrázku č. 1 jsou zobrazeny výskyty slov zbraň, bajonet, voják, tank a dělo v anglickém jazykovém korpusu. Je vidět, že se tato slova častěji používala v době válečných konfliktů. S rozvojem vojenské techniky začal na významu nabývat tank, zatímco dělo a bajonet zaznamenává ústup.
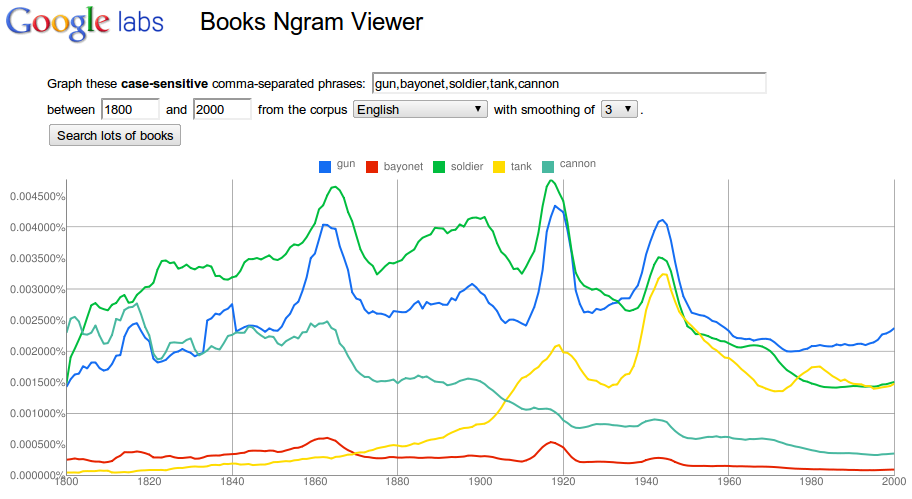
Obr. 1: Výskyt slov zbraň, bajonet, voják, tank a dělo v anglickém korpusu
Na obrázcích 2 až 4 je zobrazen výskyt slova telegraf postupně ve francouzském, britském a německém korpusu. Ve francouzské tištěné knižní produkci se podle dat z Ngramu slovo telegraf zaznamenalo po roce 1840 poměrně prudký nárůst, vrcholu je zaznamenán přibližně mezi lety 1850 až 1870 a od té doby již jeho užívání pomalu klesá. V britské tištěné knižní produkci je nárůst pozvolnější, vrchol je zaznamenám až po roce 1910, od roku 1920 opět jeho užívání klesá. Křivka užití slova telegraf má v německém korpusu zcela jiný průběh s několika vrcholy (kolem roku 1870, 1960-1980 a před rokem 2000). V některých letech to dokonce vypadá, jako kdyby data chyběla, což může mít příčinu v menším zastoupení německy psaných knih, které lze prohledávat.
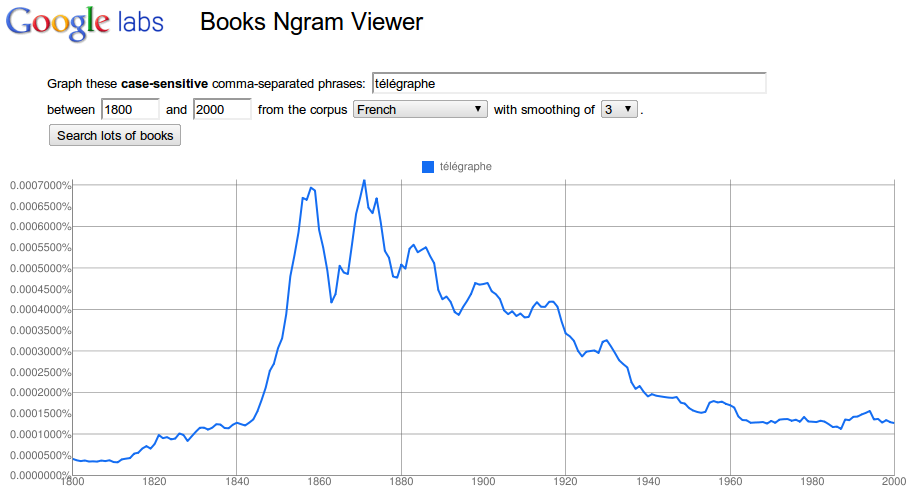
Obr. 2: Výskyt slova telegraf ve francouzském jazykovém korpusu
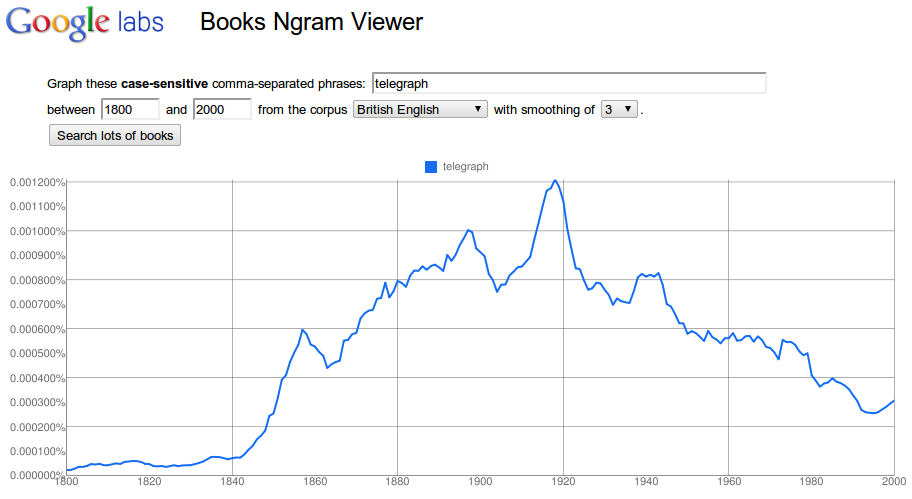
Obr. 3: Výskyt slova telegraf v britském jazykovém korpusu
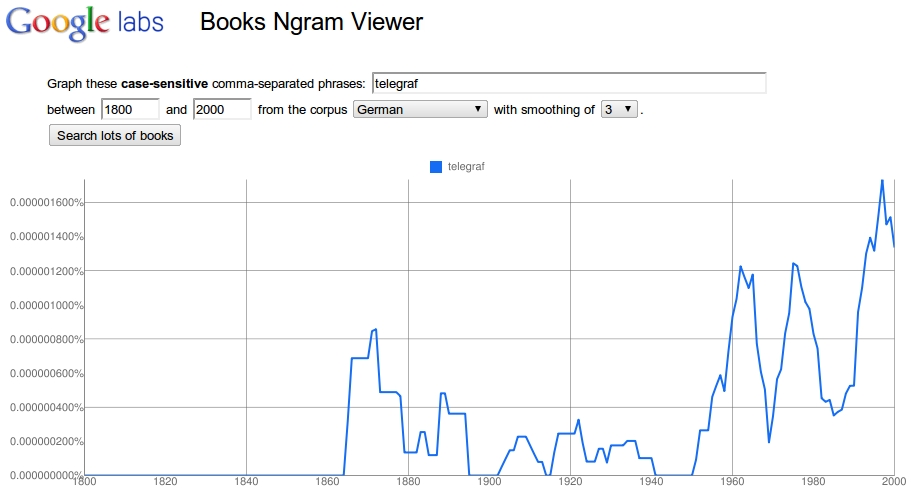
Obr. 4: Výskyt slova telegraf v německém jazykovém korpusu
- Google Books Ngram Viewer – unikátní analýza u knih od roku 1500. JustIt.cz, 17. prosince 2010 [cit. 2011-02-20]. Dostupné z WWW: <http://www.justit.cz/wordpress/2010/12/17/google-books-ngram-viewer-unikatni-analyza-z-knih-od-roku-1500/>.
- WHITNEY, Lance. Google's Ngram Viewer: A time machine for wordplay. Cnet News, December 17, 2010 [cit. 2011-02-20]. Dostupné z WWW: <http://news.cnet.com/8301-1023_3-20025979-93.html>.
- LEE HOTZ, Robert. Word-Wide Web Launches : New Google database Puts Centuries of Cultural Trends in Reach of Linguists. The Wall Street Journal, December 17, 2010 [cit. 2011-02-20]. Dostupné z WWW: <http://online.wsj.com/article/SB10001424052748704073804576023741849922006.html>.
- http://www.scientificamerican.com/article.cfm?id=google-books-culture&page=2
- HARMON, Katherine. New Tool Tracks Culture through the Centuries via Google Boooks. Scientific American, December 17, 2010 [cit. 2011-02-20]. Dostupné z WWW: <http://www.scientificamerican.com/article.cfm?id=google-books-culture>.
- ORWANT, Joh. Find out what's in a word, or five, with the Google Books Ngram Viewer. The Offiial Google Blog, 16. 12. 2010 [cit. 2011-02-20]. Dostupné z WWW: <http://googleblog.blogspot.com/2010/12/find-out-whats-in-word-or-five-with.html>.
- COHEN, Patricia. In 500 Billion Words, New Window on Culture. The New York Times, Deember 16, 2010 [cit. 2011-02-20]. Dostupné z WWW: <http://www.nytimes.com/2010/12/17/books/17words.html?_r=1>.
- GASSNER, Peter. The Google Books Ngram Viewer. 21 Dec 2010 [cit. 2011-02-20]. Dostupné z WWW: <http://datavisualization.ch/tools/the-google-books-ngram-viewer>.
- BINDER, Natalie. Google's word ngine isn't ready for prime time. The Binder Blog, December 17, 2010 [cit. 2011-02-20]. Dostupné z WWW: <http://thebinderblog.com/2010/12/17/googles-word-engine-isnt-ready-for-prime-time/>.
- BINDER, Natalie. The problem with Google's thun Description. The Binder Blog, Decemer 18, 2010 [cit. 2011-02-20]. Dostupné z WWW: <http://thebinderblog.com/2010/12/18/google-ngrams-thin-description/>.
- Google labs. Books Ngram Viewer. Google, c2010 [cit. 2011-02-20]. Dostupné z WWW: <http://ngrams.googlelabs.com/info>.