Programový projekt MK ČR
OBSAH
A.2 Současný stav ve světe a v ČR
A.1.2 Současný stav v zahraničí
A.1.3 Současný stav v ČR
A.3.2 Vstupní data
B.1.2 TOPIC
B.1.3 Standardizace - bibliografická metadata ve formátu UNIMARC a metadata DUBLIN CORE v plných textech
B.1.4 Propojení bibliografického záznamu s plným textem
B.1.5 Souborná databáze ANL Kooperačního systému článkové bibliografie (KOSABI)
B.1.6 Česká národní bibliografie - řada Články v českých novinách, časopisech a sbornících na CD-ROM
B.1.7 Management Kooperačního systému článkové bibliografie (aplikace MNG KOSABI)
B.1.8 HW a SW podpora Kooperačního systému článkové bibliografie, bibliografické báze ANL a plnotextové databáze ANL FULL
B.1.9 Smluvní ošetření projektu a Kooperačního systému článkové bibliografie
B.3 Posun znalostí
C.2 Závěr
C.3 Návrhy opatření
A Konstatační část
A.1 Rešerše (viz Použité zdroje)
A.2 Současný stav ve světě a v ČR
A.2.1 Obecně
Databáze citací článků a další sekundární zdroje informací patří v současné době mezi standardní služby, poskytované uživatelům knihoven spolu s přístupem do katalogů. Dostupné jsou z mnoha zdrojů rozptýlených po síti, z lokálních připojení, ze systémů CD-ROM. Technologie jako Z39.50 umožňují zavádění konzistentních uživatelských rozhraní pro širokou škálu databází přístupných po síti. Většina uživatelů používá databáze sekvenčně (vždy jen jednu), roste potřeba rozhraní, které by slučovalo záznamy získané z několika databází do logické "souborné" databáze. Elektronické dokumenty jsou zpřístupňovány prostřednictvím nakladatelství, distributorských firem, informačních institucí či služeb a jejich produktů, dále pak prostřednictvím digitálních knihoven a služeb vznikajících na základě projektů. Přístup k plným textů je zajišťován přes různé formy bibliografií a soupisů, obsahů časopisů a plnotextových databází. Vyhledávání v plných textech zvyšuje komfort přístupu uživatelů k informacím. Elektronické dokumenty jsou zpřístupňovány v dohodnutých formátech, např. JPEG, GIF, PDF, TIFF, HTML. Služby knihoven jsou založeny na typu služby "document delivery". Poměrně dobře jsou zpřístupňovány plné texty novin, týdeníků a jiných časopisů. Problém vytváření vazeb na primární obsah se v současnosti soustřeďuje na článkové databáze proto, že technologie přístupu k datům v síti celkem dobře umožňuje přístup k článků v elektronické podobě, zatímco přístup k jiným typům dokumentů je problematičtější. Kromě vyhledávačů typu "search engines" (Alta Vista aj.) nebo předmětových katalogů Internetu (Yahoo! aj.) registrující informační zdroje v nestrukturované podobě a u nichž relevance jejich zpětného vyhledávání je značně problematická, se přímo v prostoru Internetu a webu objevují registrační systémy, které přistupují ke zpracování těchto zdrojů přes strukturované záznamy. Tyto údaje mohou být obsažené ve zdrojích samotných (metadata). Pro popis webovských informačních zdrojů je navržen formát Dublinské jádro (DC) jako základní soubor údajů pro popis zdrojů. Dublin Core [4] může být vytvářen autorem, vydavatelem, distributorem těchto zdrojů.
A.2.2 Současný stav v zahraničí
Některé digitální knihovny, služby a projekty zabývající se zpřístupněním sekundárních informací o článcích a zpřístupněním plných textů:
UNCoverWeb [5] je databáze registrující články z časopisů na základě obsahů přebíraných asi z 18000 titulů periodik. Databáze obsahuje stručné záznamy více než 8000000 článků, které vyšly v odborných a vědeckých časopisech od r. 1988. Hlavním cílem služby je poskytování plných textů článků - placená služba.
Nejkompletnější přístup k elektronickým časopisům nabízí OCLC FirstSearch Electronic Collection Online [6]. Interface umožňuje prohledávání periodik i čísel podle různých kritérií, přístup k citacím časopisů je zdarma, přístup k abstraktům a plným textům je možný jen u předplacených titulů, je podporován konzorciální přístup včetně přístupu kombinovaného s individuálním a "document delivery".
Ve Švédsku jsou články prezentované v systému LIBRIS [7]. Záznam článku je možno zobrazit ve zkrácené podobě i ve struktuře MARC. Formulář obsahuje hypertextové odkazy na knihovny, v jejichž fondu se titul nachází.
V DBC - Dánském knihovnickém centru [8] se zpracovávají články a recenze v rámci báze BASIS (ročně 30000 článků a 20000 recenzí z 9000 dánských periodik). Toto centrum buduje souborný katalog DANBIB [9], přes který lze zaslat objednávku elektronické kopie článku. Je propojený se švédským souborným katalogem LIBRIS a norským souborným katalogem BIBSYS [10].
Universitní knihovna v Helsinkách (plní funkci finské národní knihovny) provozuje centrální knihovnický systém VTLS sítě Linnea, v rámci které je zpřístupňována databáze článků ARTO [11] z tisíce finských periodik.
NORDINFO [12] - projekt skandinávského souborného virtuálního katalogu zohledňuje aspekty specifické pro severské země - předmětová hesla, klasifikační systémy, národní systémy identifikátorů.
The Nordic Metadata Project [13] - kooperační projekt severských zemí jako jeden z prvních řeší problematiku metadat Dublin Core [4] v rámci spolupráce Norska, Dánska, Švédska, Finska a Islandu.
Systém knihoven Oxfordské university [14] zpřístupňuje rozsáhlou sbírku elektronických dokumentů v rámci Electronic Reference Library. Záznamy článků obsahují krátké citace, abstrakty a možnost získání elektronické kopie ve formátu PDF.
Program PICA v Holandsku [15] zajišťuje přístup k centralizovaným bibliografickým databázím a zejména vytváří tzv. Otevřenou síť knihoven (OBN - Open Bibliotheek Netwerk), v rámci které je umožněno elektronické propojení knihoven s databází článků.
V Německu je vyvinut projekt JADE (Journal Articles Database) ve spolupráci s British Library. Obsahuje pouze krátké citace článků (tato báze obsahuje i záznamy z NKČR). JADE je doplněn projektem JASON [16] (Journal Article Send On Demand). JASON umožňuje dodávání článků v elektronické podobě z německé databáze časopisů.
A.2.3 Současný stav v ČR
Některé digitální knihovny, služby a projekty zabývající se zpřístupněním sekundárních informací o článcích a zpřístupněním plných textů:
České nakladatelské elektronické zdroje na Internetu jsou ve stádiu vývoje a hledání podoby. Vztahy mezi uživateli, knihovnami a vydavateli/nakladateli nejsou dosud jasné z hlediska právního i obchodního, v budoucnu lze předpokládat v tomto směru vznik nových iniciativ.
Nakladatelství Economia, a. s. [17] vystavuje na Internetu plné texty Hospodářských novin a časopisu Ekonom. Je možno předpokládat vystavení dalších titulů z produkce tohoto nakladatelství. Objevují se specializovaná elektronická nakladatelství (např. Sagit - zpřístupňuje plná znění zákonů, Portál, Muzikus aj.).
Albertina icome Praha [18] je česká soukromá společnost zaměřená na zpřístupnění profesionálních informačních zdrojů v elektronické formě a jejich využití v praxi. AiP nabízí přes 1000 elektronických titulů předních světových vydavatelství. Elektronické vydavatelství spolupracuje na vydávání ČNB na CD-ROM.
V České republice existují některé oborové báze plnotextových informací, např. ASPI (Automatizovaný systém právních informací [19]) zachycuje vývoj právní kultury, vztahující se k území současné České republiky i Slovenské republiky v rozsahu dvou století s výhledem na legislativu Evropských společenství.
Akademie věd ČR zpřístupňuje na Internetu current contents a abstrakty článků z časopisů [20] vydávaných AV prostřednictvím jednotlivých redakcí časopisů (plné texty zatím ojediněle).
V rámci Parlamentní knihovny [21] se buduje systém, ve kterém jsou zpřístupněna v plné formě parlamentária.
Relativně velký rozvoj na Internetu nastal v nabídce českých novinových a časopiseckých elektronických zdrojů - jsou vystaveny deníky, týdeníky a časopisy s různou hloubkou retrospektivy a úplnosti od volně přístupných přes registraci a služby placené. V některých elektronických zdrojích lze vyhledávat plnotextově.
Např. Seznam [22] je katalogový a vyhledávací server se službou Kompas, která umožňuje plnotextové vyhledávání www stránek českého Internetu. V lednu 1999 se změnila základní podoba Trafiky - virtuální Trafika [23] se mění v pravý český portál. Je možno zde najít informace o článcích z novin a časopisů, dále pak elektronické časopisy a magazíny vydávané M.I.A (Svět Namodro aj.). Trafika nabízí z vlastní produkce následující tituly aktuálně v portálové podobě: Mladá fronta Dnes, Lidové noviny, Právo, Slovo, Týden, Mladý svět, Respekt aj. Politika, metody a strategie vystavování těchto zdrojů na Internetu se často mění, u některých je však možnost vysledovat určitou stálost a uvažovat o propojení s analytickými záznamy. Propojování s volně přístupnými zdroji na Internetu však musí být velmi obezřetné.
Na českém informačním trhu působí dvě společnosti, které se zabývají zpřístupňováním plných textů programově. Společnost Anopress, s. r. o. [24] a společnost Newton I.T., s. r. o. [25] Obě společnosti získávají na základě smluv s jednotlivými vydavateli plná znění deníků a dalších periodik. Převod článků do tvaru vhodného k dalšímu zpracování se děje pomocí vlastních patentových postupů a zajišťuje věrnost původní předlohy. Obě společnosti vlastní archiv titulů celostátních, regionálních a dalších včetně jejich mutací, dále pak přepisy televizních a rozhlasových pořadů. Poskytované služby obou společností se však liší.
Newton I.T., s. r. o. poskytuje plné texty v rámci služby Media Monitoring na základě individuálních požadavků. Neumožňuje přímý přístup do celé databanky.
ČTK [26] je národní informační agentura a zabývá se sběrem, zpracováním a distribucí zpravodajství a informací ze všech oblastí lidské činnosti.
Anopress, s. r. o. umožňuje on-line přístup do databanky plných textů TAMTAM [27], na jejíž bázi poskytuje následné služby. Společnost zpřístupňuje informace zákazníkovi na dané téma. Anopress, s. r. o. umožňuje přístup do databanky novin on-line na základě licenčních smluv a umožňuje nákup celých titulů periodik. Společnost Anopress je výhradním zpracovatelem elektronické podoby většiny českých regionálních (51 titulů nakladatelství Bohemia). Pro zpřístupnění plných textů ve veřejných knihovnách bylo založeno Konzorcium Anopress, s. r. o. [28]
Společnost Anopress je výhradním zástupcem slovenské firmy SLOVAKIA ONLINE v ČR, která zpracovává elektronickou podobu slovenských tištěných médii. Kromě mediální části obsahuje databanka TAMTAM i část vědomostní, v níž jsou k dispozici pro fulltextové vyhledávání různé encyklopedie, příručky a další knihy referenčního charakteru.
Společnost vyvinula vlastní software ISA, který umožňuje všechna data dále analyticky zpracovávat, exportovat je v několika formátech, včetně HTML, pro Internet či Intranet. Vyhledávací systém americké firmy Verity TOPIC [29], který Anopress používá k monitoringu a analýze informačních zdrojů, je v současnosti jediným interaktivním systémem na českém trhu. Automaticky vyhodnocuje relevanci dokumentů a umožňuje jejich řazení podle důležitosti. Na rozdíl od zdlouhavého fulltextového vyhledávání jde v tomto případě o pojmové, tzv. inteligentní vyhledávání, šité přímo na míru požadavkům uživatele. Anopress ve spolupráci s Národní knihovnou ČR [30] vytváří v rámci tohoto projektu technologii, která umožní propojit bibliografické záznamy knihovny s plnými texty článků z databáze Anopress, dále pak vkládat bibliografická metadata do analytických záznamů a metadata typu Dublin Core [4] do plných textů.
Anopress zpracovává cca 35 titulů, které odpovídají excerpční základně Kooperačního systému článkové bibliografie [31].
Bibliografické zpracování článků v ČR je poměrně rozsáhlé jak co do zdrojů, které se analyticky zpracovávají, tak co do typů institucí, které tuto činnost provozují.
Národní knihovna ČR zpracovává výběrově bibliografické záznamy článků [32] ze všech druhů seriálů (noviny, časopisy, odborná periodika, sborníky) v rámci Kooperačního systému článkové bibliografie [31] (KOSABI), ve kterém spolupracují stávající SVK a MZK, specializované odborné knihovny (STK, ÚZPI, SPKK-ÚIV, ČSAV). Na základě této spolupráce vzniká souborná databáze ANL [33].
V systému LANIUS [31] se zpracovávají bibliografické záznamy článků v knihovnách na úrovni okresů. V budoucnu je třeba sladit systém KOSABI a LANIUS tak, aby nedocházelo k duplicitnímu zpracování. V současné době se postupně v rámci KOSABI aplikuje nebo plánuje přechod na nové SW vyšší generace, zatím probíhá ve většině SVK popis článků v ISISu. V SVK Kladno se články popisují v systému RAPID, v MZK v Brně v ALEPH. V době přechodu spolupracujících institucí na různé nové integrované systémy (KP-SYS, TINLIB, RAPID apod.) je kvalitní automatizovaná správa souborné databáze nutná. Souborná databáze KOSABI ANL obsahuje přes 620 000 záznamů, v NKČR se excerpuje se cca 210 titulů, 469 titulů ve spolupracujících institucích (278 specializované knihovny, 191 titulů v SVK a MZK). Přechod na zpracování v systému v ALEPH 500 v dubnu 2000 posunulo zpracování na úroveň mezinárodního formátu UNIMARC a pravidel popisu AACR2 s respektováním mezinárodních standardů věcného popisu - MDT-MRF pro oblast systematické indexace. V oblasti verbální věcné indexace se kombinují klíčová slova, věcné obecné kategorie a předmětová hesla. Vyváženost vazby mezi jednotlivými vrstvami popisu je klíčovým momentem. V rámci kooperačního systému byla stanovena pravidla pro výběr titulů k popisu (na základě územní gesce - tituly regionální a celostátní provenience a dále pak na základě odborného zaměření). Dále byly stanoveny zásady výběru článků co do úplnosti i co typů.
V posledních letech vzniká několik projektů, zabývajících se zpřístupněním analytických záznamů v kooperaci s ostatními knihovnami, jejich prezentací na Internetu a propojením těchto záznamů s plnými texty.
Zpřístupnění výsledků analytického zpracování prostřednictvím Internetu (kooperační projekt 13 knihoven v rámci programu RISK, řešený v r. 1998, hlavní řešitel Ivana Anděrová) umožnil konverzi analytických záznamů z CDS/ISIS do UNIMARCu. V rámci projektu byla vypracována a odzkoušena konverze tehdejší verze Tinlibu do UNIMARCu. V rámci průzkumu Internetu se ukázalo, že postupné propojení článků s některými plnými texty již vystavovanými na Internetu na různých serverech je krajně nespolehlivé (různá retrospektiva a úplnost vystavovaných plných textů, různá strategie vystavovatelů). Výběr spolehlivých zdrojů plných textů je možné řešení.
Propojení analytických záznamů s plnými texty a optimalizace zpřístupnění plných textů [34] (VaV, hlavní řešitel Ivana Anděrová, r. 1999-2003) - je projekt analyticko-koncepční a připravuje půdu pro praktickou realizaci účelového projektu popisovaném v této zprávě a dalších projektů. Cílem výzkumného záměru je optimalizace přístupu uživatelů k plným textům dokumentů domácí provenience (nikoli zahraniční). Základem je propojení analytických záznamů o článcích s plnými texty, které jsou dostupné na Internetu a/nebo CD-ROM. V rámci projektu v r. 1999 proběhlo v NK výběrové řízení a na základě výše uvedených faktů byla vypracována výzva k podání nabídky pro společnost Anopress. V rámci projektu bylo vyvinuta iniciativa k vytvoření Konzorcia Anopress, s. r. o. Smlouva Konsorcium uživatelů databanky TAMTAM informační agentury Anopress, s. r. o. byla podepsána mezi SKIP a Anopressem v r. 2000. V r. 1999 bylo experimentálně propojeno cca 4000 záznamů s plnými texty, získanými od Anopressu a některá odborná knihovnická periodika.
Periodikum Národní knihovna bylo v Anopressu převedeno do digitální formy [35] a zpřístupněno na Internetu (v r. 1999 pouze technikou OCR, v r. 2000 se přistoupilo i k prezentaci obrázků).
Projekt Západočeský ANAL - Kooperativní zpracování periodické produkce západních Čech (SVK v Plzni a 11 městských knihoven, řešitel Jaroslava Hanzlíčková, RISK, podaný v r. 1999) se zabývá odstraněním duplicit při zpracování, metodikou excerpce titulů a zpracování záznamů v jednotlivých okresech západočeského regionu.
Projekt Zavedení automatizovaného zpracování článkové bibliografie v systému T-Series (SVK v Ostravě, hlavní řešitel Alena Hrazdilová, VaV, r. 2000-2001) řeší problematiku bibliografického zpracování článků v tomto systému.
Právě podávaný projekt SVK Kladno je velmi významný z hlediska tvorby a rozvoje regionálních faktografických databází a souborů autorit.
Analytické záznamy zpracovávané v rámci KOSABI [31] jsou zpřístupňované také na CD-ROM vydávaném AIP icome v rámci ČNB jako řada Články v českých novinách, časopisech a sbornících [36], od června v 2000 v UNIMARCu. CD-ROM je vydáván ve čtvrtletních aktualizacích, každý měsíc je vystavena aktualizace [37] na Internetu.
A.3 Cíl, vstupní data
A.3.1 Cíl
Náplní projektu je optimalizace integrace a správy heterogenních dat souborné databáze Kooperačního systému článkové bibliografie. Bibliografické záznamy článků, publikovaných v českém periodickém tisku a zpracovávané spolupracujícími knihovnami, budou postupně propojované s elektronickou podobou článku a takto prezentované na Internetu. Obě části souborné databáze - vznikající databáze plných textů a báze bibliografických záznamů ve formátu UNIMARC - vyžadují permanentní kvalitní SW a HW podporu.
Budování, doplňování, správu a údržbu plnotextové databáze s možností vyhledávání
zajistí informační agentura Anopress. Zároveň půjde o vývoj
manažerského systému pro příjem a správu dat kooperačního systému. Hlavním cílem projektu je zkvalitnění bibliograficko-informačních služeb.
Cílem projektu v roce 2000 je průběžné doplňování báze ANL [33] v rámci KOSABI [31] klasickým způsobem a publikovat ji v rámci ČNB - řada Články v českých novinách, časopisech a sbornících [37], dále návrh řešení linky automatického přebírání plných textů a automatické indexace bibliografických záznamů pro bázi ANL a tvorby URL, budování databáze plných textů ANL FULL s možností pojmového vyhledávání, dále pak řešení automatické správy - managementu KOSABI. V roce 2000 je třeba vybavit systém odpovídajícím SW a HW a ošetřit smluvně.
Návrh řešení pro rok 2000 spočívá v zavedení nových metod v rámci získávání informací (možnost konzorciálního nákupu), zpracování bibliografických záznamů (přebírání metadat) a zpřístupňování informací (propojení záznamů s plnými texty a vyhledávání v plných textech).
Řešení otázek standardizace jmenného a věcného popisu bibliografických záznamů a elektronických dokumentů a možnosti přebírání metadat do bibliografických záznamů ve formátu UNIMARC a plných textů v podobě Dublin Core [4] je nutným předpokladem funkčnosti celého systému.
Cílem v roce 2000 je dále průběžné ukládání plných textů ze současné produkce deníků a některých odborných časopisů odpovídající profilu NK na serveru NK a částečná příprava k dynamickému propojení přes komponentu URL uloženou v propojovacím poli bibliografických záznamů.
(Plné texty článků regionální provenience budou pravděpodobně v budoucnu uloženy na serveru Anopressu - mohou být uloženy i na serverech jednotlivých knihoven. Záznamy z let minulých budou postupně propojovány během řešení celého projektu v letech 2001-2004 s plnými texty metodou off line).
Dalším cílem v roce 2000 je zpracování bibliografických záznamů v NK ČR a napojení na plné texty s úplnými statickými URL adresami - záznamy především titulů z oboru knihovnictví a oblasti práva aj. oborů.
A.3.2 Vstupní data
Vstupními daty pro bázi ANL jsou jednak bibliografické záznamy zpracovávané v r. 2000 v rámci KOSABI [31], bibliografické záznamy zpracované v NK ČR a doplňované částečnými URL pracovníky oddělení a k nim plné texty pro bázi ANL FULL [33] stažené v rámci Konzorcia Anopress [28] taktéž pracovníky oddělení. V roce 2000 se jedná zejména o tituly zpracovávané v NK ČR, a to analyticky zpracovaný výběr z celostátních deníků a některých časopisů (Týden, Ekonom, Respekt, Reflex). Vstupními daty pro bázi ANL FULL jsou tedy plné texty, které odpovídají profilu zpracování bibliografických záznamů.
Záznamy takto zpracované a zároveň zaindexované plné texty s Dublin Core [4] jsou takto připraveny k dynamickému propojení.
Vstupními daty jsou dále bibliografické záznamy zpracované v NK ČR a napojované na plné texty s úplnými (statickými) URL adresami - záznamy především titulů z oboru knihovnictví (Národní knihovna, U nás, Ikaros, Daidalos aj.) a oblasti práva (Veřejná správa, Obchodní právo, právo a podnikání, Moderní obec aj. - napojení na plné texty zákonů), dále pak záznamy z některých odborných periodik a plné texty dostupné na Internetu (Vesmír, Collection of Czechoslovak Chemical Communication aj. vydané v r. 2000).
Vstupními daty pro léta minulá jsou bibliografické záznamy a adekvátní plné texty článků z novin a některých odborných časopisů (v roce 2000 je to výběr produkce bibliografických záznamu a plných textů za léta 1998, 1999).
Summa summarum:
Vstupními daty pro plnotextovou bázi ANL FULL jsou plné texty zejména celostátních deníků a některých odborných časopisů za rok 1999, 2000, 1998 a jim odpovídající bibliografické záznamy v tomtéž období pro bázi ANL [33] v rámci KOSABI [31].
Vstupními daty pro návrh automatizované linky zpracování bibliografických záznamů jsou to plné texty získané z databáze TAMTAM [27]. V rámci této linky vznikají vstupní data pro bibliografickou bázi ANL [33] a plnotextovou databázi ANL FULL [33].
B Analytická část
B.1 Vlastní řešení
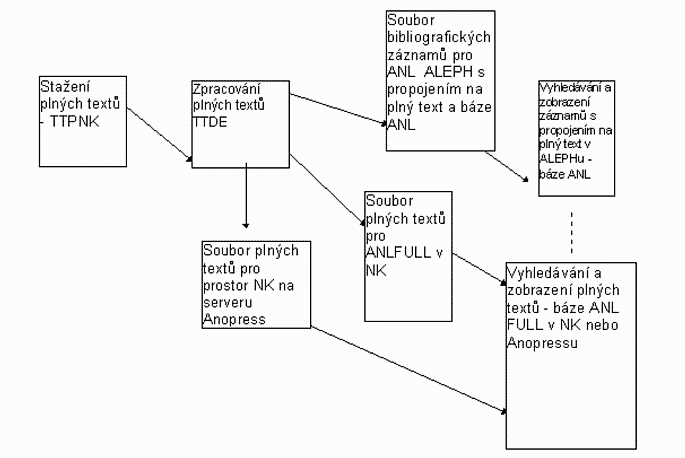
B.1.1 Linka automatické indexace [Obr. 1 [38]]
{kind=link}
Pro optimalizaci integrace a správy heterogenních dat souborné databáze kooperačního vyvinula česká firma Anopress na podkladě analýzy a funkčního zadání návrh speciální technologie - linky automatického získávání plných textů, indexace bibliografických záznamů a plných textů, propojování záznamů na plné texty a jejich zpřístupnění. Řešení je progresivní a odpovídá nejnovějším trendům v této oblasti , je podpořeno kvalitním technickým a programovým vybavením. Jednotlivé moduly lze použít i samostatně. V rámci experimentu v r. 2001 je třeba ještě doladit technologii v rámci různých stádií aplikace.
Řešení spočívá ve speciální aplikaci v praxi již používané technologie firmy na získávání a zpřístupňování plných textů pro NK - TAMTAM Profesional NK (TTPNK). Pomocí této technologie je možno stahovat plné texty článků z Internetu z báze TAMTAM, založené na plnotextovém pojmovém vyhledávání systému TOPIC. Je možno stahovat více článků najednou na základě tématu, názvu článku, názvu zdrojového dokumentu a dalších údajů. (Pro stahování je možné využít i verzi TAMTAM Standard - TTS).
Pro vlastní automatickou indexaci článků a plných textů - pro vytváření bibliografických záznamů v UNIMARCU na základě údajů uložených v plných textech a naopak pro vkládání metadat Dublin Core plných textů je připravena technologie TAMTAM Data Extractor (TTDE).
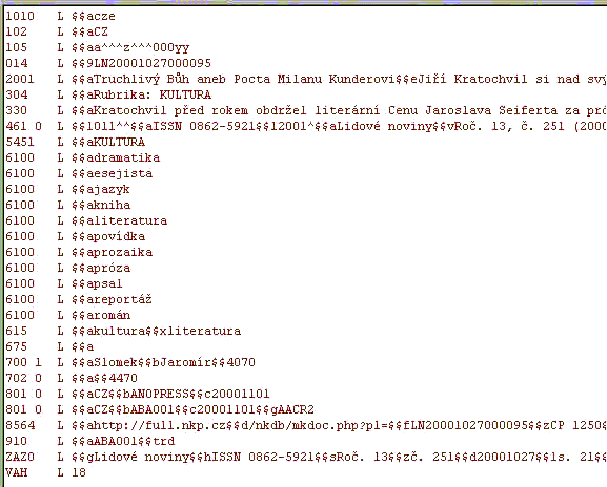
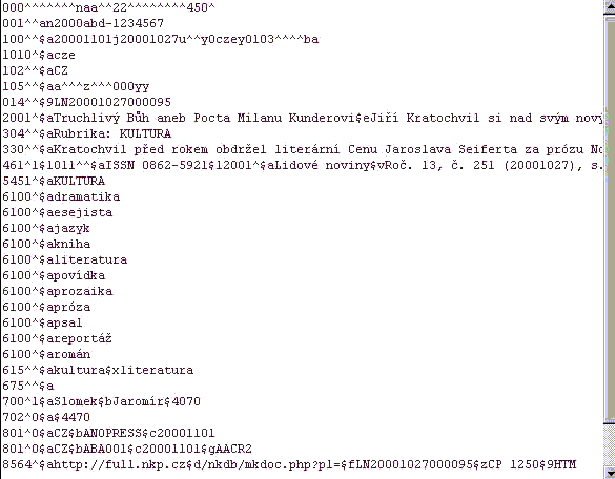
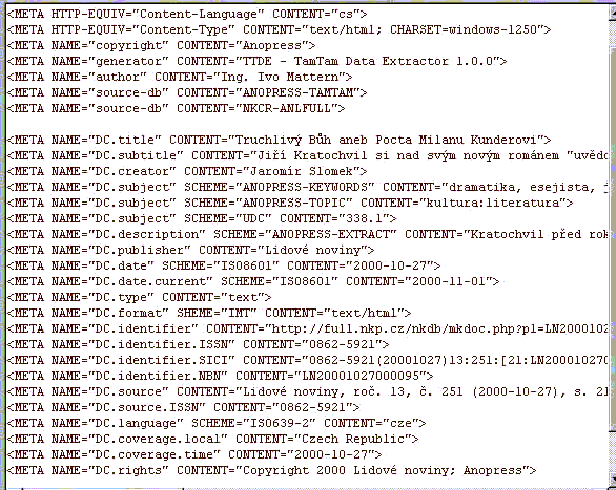
Bylo připraveno 6 hlaviček (headers) [Obr. 2 [39]], které se automaticky generují z plného textu : Formulář pro editaci [Obr. 2 [39]], do kterého se generují bibliografická data z plného textu. Data lze katalogizátorem následně upravovat a provádět tak korekce nejen ve Formuláři, ale automaticky také v hlavičce UNIMARC [Obr. 3 [39]], UNIMARC [Obr. 4 [40]], Dublin hlavičce [Obr. 5 [41]]. Obsahuje údaje jmenného popisu, které se přebírají z hlavičky plného textu (oproti původním údajům byly doplněny údaje roč., číslo, ISSN), dále pak obsahuje údaje věcného popisu (předmětové kategorie, automaticky generovaná klíčová slova, automaticky generovaný abstrakt - extrakt), automaticky generovanou URL složenou z jednotlivých komponent odpovídající struktuře propojovacího pole 856 ALEPH a UNIMARC. Volbou Text na horní liště je možno zobrazit plný text.
{kind=link}
{kind=link}
{kind=link}
UNIMARC hlavička [Obr. 3 [39]] je hlavička s bibliografickými údaji pro importní vstupní soubor záznamů pro ALEPH (řádkový UNIMARC), do které se automaticky generují taktéž data jako do Formuláře a úpravy zanesené do Formuláře, tato hlavička je také přístupná pro editaci samostatně.
UNIMARC hlavička [Obr. 4 [40]], hlavička pro klasický UNIMARC s týmiž vlastnostmi jako hlavička UNIMARC - slouží k eventuálnímu importu pro systémy , které jsou založeny na UNIMARC - řádkový UNIMARC. Do hlavičky jsou generované tytéž údaje jako do výše jmenovaných hlaviček.
DUBLIN hlavička [Obr. 5 [41]] s týmiž vlastnostmi jako předchozí dvě hlavičky sloužící ke generování metadat Dublin Core zpět do plného textu - slouží k zabudování těchto metadat do plných textů pro fulltextovou databázi - vychází z poslední verze Dublin Core Metadata Set, obsahuje navíc automaticky generované SICI (Serial Item and Contribution Identifier [42]) a provizorní NBN (National Bibliography Number).
Indexovací hlavička obsahuje údaje jmenného popisu.
Zobrazovací hlavička slouží k zobrazení údajů v hlavičce plného textu.
Po odrážce různé je možno nastavit tvar výstupní hlavičky pro UNIMARC [Obr. 3 [39]] nebo UNIMARC [Obr. 4 [40]] a spustit ruční vstup dat.
Dále následuje přesunutí UNMIARC [Obr. 3 [39]] hlavičky do importu pro ALEPH (báze ANL) a umístění plných textů ve tvaru HTML na web server NK k indexaci do fulltextové databáze v NK nebo do Anopressu.
Pro indexaci dat do fulltextové databáze (ANL FULL) v NK byl vyvinut program MkIndex (MkI). Tento program nalezená data automaticky zaindexuje, umožňuje jejich vyhledání ve fulltextové databázi a zpřístupnění. Plné texty jsou ve formátu HTML.
Pro vyhledávání v datech ve fulltextové databázi jsou vyvinuty formuláře pro vyhledávání jednoduché, pokročilé, pokročilé s tématy [Obr. 6 [43]]. Vyhledávání probíhá v systému TOPIC (Search 97) a definice formulářů vychází z jeho filozofie.
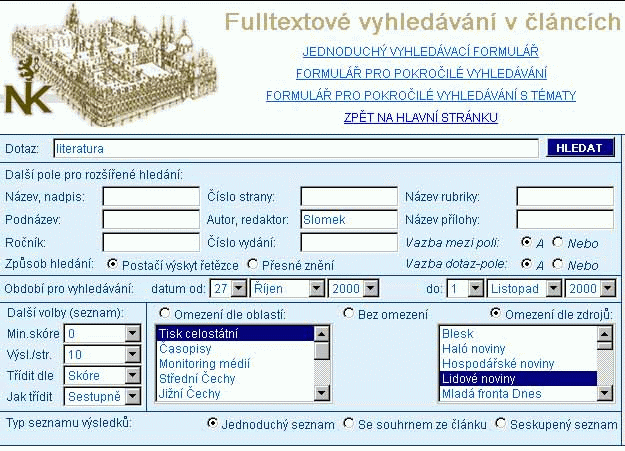{kind=link}
V budoucnu bude Formulář pro editaci pravděpodobně rozšířen o některé údaje věcného popisu. Pro import do ALEPH je třeba připravit převodní tabulky mezi kódem 1250 CP do Ansel, používaného v ALEPH nyní a budoucím Unicode.
Pro propojení plných textů se systémem ALEPH (doplnění URL adres do záznamů) byl vytvořen skript mkdoc.http. Propojení probíhá ne základě dynamicky generovaného odkazu na dokument. Program vyhledá požadovaný dokument dle identifikace (identifikační číslo), provede statistiku a v budoucnu bude provádět kontrolu autorizace a na jejím základě zobrazí plný text, abstrakt nebo nic.
B.1.2 TOPIC [29]
TOPIC (pojmově orientovaný vyhledávací systém, concept based retrieval) je systém třetí generace založený na následujících principech: rozklad pojmu na podpojmy, vážení jednotlivých podpojmů (větví pojmového stromu), neostré vyhodnocování dotazů. Dotaz v systému třetí generace reprezentuje pojem, resp. ideu vyhledávaného tématu. Jádrem dotazu je stromová hierarchická struktura, která rozkládá hledané téma na podtémata a přiřazuje jednotlivým částem váhy, které vyjadřují do jaké míry příslušné téma přispívá k celkovému určení tématu. Systém dále vypočítá míru relevance vyhledaných dokumentů. Oproti běžně používaným operátorům TOPIC používá logický operátor ACCRUE se specifickými vlastnostmi. Tento operátor sbližuje operátory and a or. Každý topik obsahuje tedy tři charakteristiky - strukturu, váhy a operátory.
Nabízí se zde jistá formální analogie k hierarchickému selekčnímu jazyku systémové notace MDT. Je však třeba zdůraznit, že topiky jsou tvořeny podle skutečnosti, MDT je víceméně taxativní systém jednotlivých oborů, nikoli témat. Proto je třeba k definici topiků přistupovat svébytně.
Dotaz lze zadávat třemi způsoby:
Prostý dotaz je pouze seznam slov, které se mohou vyhledat. Všechna slova mají stejnou váhu - možno použít při hrubém hledání, kdy se přesně neví, co se má vyhledat.
Formulářový dotaz slouží k přesnějšímu vymezení dané oblasti. Dotaz lze specifikovat dalšími atributy, jako např. autor, zdroj, datum atd.
Tematický dotaz je nejpřesnější. Spočívá ve vytvoření topiku, kdy mohou být zadány všechny váhy.
V roce 2000 byl vypracován experimentálně topik pro obor Demografie [Obr. 7 [44]], plánují se topiky další. V oddělení analytického zpracování při věcném popisu článků se používají k indexaci hrubých témat a podtémat předmětové kategorie, které připomínají svou podstatou topiky, resp. témata a skupiny témat v systému TOPIC v databázi Anopress. Je však třeba je sladit obsahově.
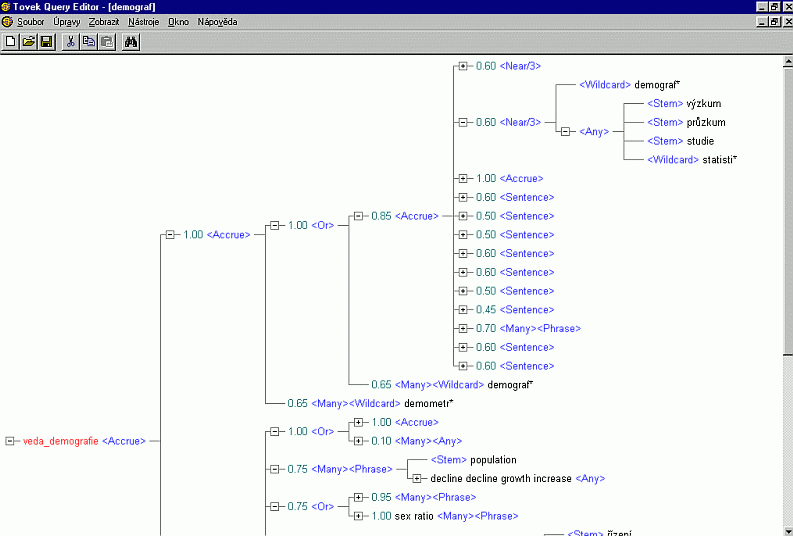{kind=link}
B.1.3 Standardizace - bibliografická metadata ve formátu UNIMARC a metadata Dublin Core v plných textech
Struktura bibliografických dat respektuje formát UNIMARC a knihovnická pravidla AACR2 v oblasti jmenného popisu. V oblasti věcného popisu se používá aktualizovaná verze MDT-MRF [45]. Verbální věcný popis obsahuje předmětové kategorie, které zasazují dokument do širších souvislostí v rámci databáze z hlediska obecných témat, jež by se měla sbližovat s tématy systému TOPIC, dále pak klíčová slova, která jsou dále částečně řízená a předmětová hesla. V budoucnu se předpokládá intenzivnější využívaní vznikajících souborů autorit jmenných i věcných. V záznamech určených k propojení s plným textem je zapracována celá URL adresa (statická) nebo komponenta dynamické URL adresy.
Struktura metadat v plných textech vychází z poslední verze Dublin Core Metadata Set. K identifikaci plného textu je zabudováno URL, SICI (Serial Item and Contribution Identifier [42]), NBN (National Identification Number) zatím používající identifikační číslo plného textu Anopressu a ISSN [Obr. 5 [41]]. Všechny tyto údaje mohou sloužit k tvorbě dynamických adres jako komponenty a k tvorbě URN (Uniform Resource Name) a URI (Uniform Resource Identifier). Do HTML je také třeba zabudovat LINK tag pro potřeby odkazu na webovský zdroj, v němž se nachází specifikace daného použitého soboru metadat.
B.1.4 Propojení bibliografického záznamu s plným textem
V databázi ANL se používají jednak statické adresy u propojení na plný text, kde se zdá strategie jeho vystavování poměrně stálá (knihovnické časopisy - Národní knihovna, U nás, Ikaros, Daidalos aj.), některé zdroje z oblasti práva aj. oborů. S těmito zdroji jsou propojovány např. záznamy z časopisů Veřejná správa, Obchodní právo, právo a podnikání, Moderní obec. Staticky jsou také propojovány plné texty dalších odborných časopisů vystavených na Internetu (Vesmír aj.).Staticky byly propojovány také záznamy z deníků v r. 1999. V plánu je další propojování s plnými texty vystavovanými na Internetu.
V oddělení analytického zpracování byly připravené záznamy k propojení s plnými texty na základě komponenty URL adresy - identifikačního čísla plného textu. Tyto adresy mohou být doplněny o další komponenty "na stálo" nebo mohou být použity k dynamickému propojování v rámci otevřených URL adres. Zatím bylo takto připraveno cca 5500 záznamů a staženo odpovídající množství plných textů článků vydaných v 2. pololetí r. 2000. Dále bylo zakoupeno cca 17930 plných textů článků publikovaných v l. pololetí r. 2000 a v r. 1998 (rok 1999 byl saturován z grantu Propojení analytických záznamů s plnými texty a optimalizace zpřístupnění plných textů).
B.1.5 Souborná databáze ANL Kooperačního systému článkové bibliografie (KOSABI)
V roce 2000 přešlo oddělení analytického zpracování na ALEPH 500 a UNIMARC (do té doby probíhalo zpracování v CDS/ISIS a záznamy se konvertovaly do UNIMARC a vystavovaly na WWW). Kooperující instituce přispívají pravidelně do souborné databáze (kromě SVK České Budějovice - čeká se na konverzi T-Series do UNIMARCu a MZK v Brně - souvisí s přechodem na novou verzi ALEPHu). Kromě toho instituce budují své lokální databáze. Záznamy respektují metodický materiál [46] Záznam pro soubornou databázi : UNIMARC a Záznam pro soubornou databázi : Výměnný formát. Byla aktualizována pracovní verze metodické příručky pro zpracování článků v UNIMARCu.
V roce 2000 probíhaly rozsáhlé korektury báze. Chybovost v bázi je z velké části dána existencí dvou podob báze v minulosti - v ISIS a UNIMARC - a způsobem zpracování v CDS/ISIS. Opravy v databázi si vyžadují průběžnou pozornost, chybovost je stále velká na straně NK i spolupracujících institucí.
B.1.6 Česká národní bibliografie - řada Články v českých novinách, časopisech a sbornících na CD-ROM
V červnu 2000 vyšel za spolupráce NKČR a AIP icome první CD-ROM [36] s články v UNIMARC. V UNIMARC vycházejí aktualizace ČNB na Internetu [37].
B.1.7 Management Kooperačního systému článkové bibliografie (aplikace MNG KOSABI)
Na základě zadání pro řízení a správu kooperačního systému a za využití již vyvinutých řešení v rámci Souborného katalogu CASLIN [47] probíhají práce na vývoji aplikace pro tento systém. V současné době je nainstalován na server ANL systém LINUX a ORACLE, ve stádiu řešení je aplikace pro příjem a automatizované zpracování dat (příjímání analytických záznamů, integrace stávajících programů pro konverzi analytických záznamů, globální úpravy analytických záznamů, vývoj programů na formálně logické kontroly kooperujících knihoven - test na UNIMARC pro analytické záznamy).
B.1.8 HW a SW podpora Kooperačního systému článkové bibliografie, bibliografické báze ANL a plnotextové databáze ANL FULL
Pro management kooperačního systému byl zakoupen PC Pentium III, 700 MhZ, ORACLE 8i server. Release 8.1.5.
Pro správu a údržbu plnotextové databáze ANL FULL byl zakoupen server DELL - PowerEDge 6300 - Pentium III Xeon 500Mhz/512, Search Verity Information Server (TOPIC) v. 3.6 pro jednoprocesorový server Windows NT zatím pro ultranet, Windows NT v. 4.0. (server full.nkp.cz)
B.1.9 Smluvní ošetření projektu a Kooperačního systému článkové bibliografie
Pro automatickou indexaci, správu (údržbu) plnotextové databáze a dodávku plných textů byly uzavřeny dvě smlouvy s Anopressem a jeho pracovníky. Dále byla uzavřena Smlouva na vývoj aplikace pro management kooperačního systému.
V listopadu byl podepsán Dodatek č. 3 ke Smlouvě o sdružení pro Českou národní bibliografii, který zabezpečuje fungování Kooperačního systému článkové bibliografie v situaci reformy státní správy. Do tohoto dodatku nebyly zahrnuty odborné knihovny (bohužel). S těmito knihovnami je třeba aktualizovat stávající smlouvy (kooperuje se dosud 1 Kč/záznam) alespoň tak, že budou dostávat v rámci spolupráce CD-ROM s ČNB jako ostatní knihovny.
B.2 Přínos řešitele
Přínos projektu spočívá v integraci elektronických zdrojů mezi tradičně zpřístupňované sekundární informace formou bibliografických záznamů. Jde o integraci heterogenních dat do Kooperačního systému článkové bibliografie [31], v němž dochází k propojení tradičních knihovnických postupů a fondů s určitými prvky digitální knihovny.
Přínos projektu spočívá v postupném budování plnotextové databáze s možností kvalitního vyhledávání založeného na principu pojmovém vyhledávání (concept based retrieval) v kombinaci s metadaty, s možností dalšího doplňování, její správy a údržby.
Další přínos projektu spočívá v rychlém zpřístupnění analytických záznamů provázaných s plnými texty zdrojových dokumentů v rámci Kooperačního systému článkové bibliografie.
Nemenší přínos v spočívá v revidování tradičních postupů při zpracování české národní bibliografie v oblasti jmenného i věcného popisu v rámci návrhu linky automatické indexace bibliografických záznamů. Pro popis webovských informačních zdrojů je aplikován formát Dublin Core, který je v současné chvíli je využíván v mnoha systémech v zahraničí.
Od spolupráce mezi Národní knihovnou a společností Anopress se očekává ekonomický efekt ve smyslu šetření pracovních kapacit Národní knihovny (generování některých bibliografických údajů a anotací). V oddělení je plánována do r. 2003 redukce o 6 pracovních úvazků ve prospěch jiných oddělení NK. V tomto roce byla realizována redukce o 2 pracovní úvazky.
Možnost vzniku duplicit či multiplicit při zpracování je minimalizováno delimitací periodik mezi spolupracující instituce. Tím má projekt další i ekonomický význam.
Další přínos spočívá ve zvýšení uživatelského komfortu - v nalezení příslušného článku z novin či časopisu (v budoucnu snad i statě se sborníku) v elektronické formě Navigace k primárním dokumentům patří k základním trendům v oblasti knihovnictví a informatiky.
Možnost aplikace vypracovaných metod na některé spolupracující subjekty v Kooperační systému článkové bibliografie v budoucnu.
Další přínos spočívá v nákupu plných textů v rámci Konzorcia Anopresss, s. r. o., což má nemalý ekonomický efekt.
Řešení navržená, programově realizovaná a částečně realizovaná v praxi v roce 2000 jsou příspěvkem do programu univerzální bibliografické kontroly (UBC) a všeobecné dostupnosti publikací (UAP) IFLA a jsou také součástí praktické realizace čl. 61 kulturní politiky o kooperaci knihoven a především čl. 63 o podpoře automatizace knihovnických systémů a propojení do globálních informačních struktur. Přispívají tak k optimalizaci veřejných informačních služeb (VIS).
B.3 Posun znalostí
K významnému posunu znalostí došlo především v těchto oblastech:
- Poměrně dobrá orientace v nových trendech zpracování a zpřístupňování informací.
- Návrh praktické realizace těchto trendů na konkrétní fungující systém, která umožní jeho přetrvání v budoucnu (metadata, pojmové vyhledávání, propojování informací, vazba na klasický fond, fond elektronických dokumentů a registrace v ČNB)
- Vytvoření předpokladů pro automatickou indexaci dokumentů.
- Propojení bibliografických záznamů s elektronickými zdroji na základě dynamických i statických URL adres, kombinace pojmového vyhledávání s metadaty jako předpoklad pro implementaci kooperačního systému do konceptu metaknihovny.
- Vytvoření předpokladů pro distribuované vyhledáván informací za současného využití tradičního slučování informací do souborné databáze založené na architektuře statických bází.
- Posílení vazby v rámci KOSABI v situaci reformy státní správy a samosprávy.
- Nová forma poskytování informačních služeb za spolupráce knihovnické a moderní informační instituce.
C Návrhová část
C.1 Výsledky řešení
- Vytvoření nástrojů pro optimalizaci integrace a správy heterogenních dat v rámci Kooperačního systému článkové bibliografie. Vznikl tak nástroj pro automatickou přípravu dat pro bibliografickou databázi založenou na UNIMARCu a plnotextovou databázi založenou na pojmovém vyhledávání systému TOPIC.
- Návrh a realizace aplikace pro získávání dat TAMTAM PROFESIONAL NK (TTPNK).
- Návrh a realizace aplikace pro automatické generování bibliografických metadat do analytických záznamů a metadat Dublin Core a jejich umístění do plných textů - TAMTAM DATA EXTRACTOR (TTDE).
- Aplikace pro indexaci dat do plnotextové databáze ANL FULL.
- Aplikace pro vyhledávání a zpřístupnění plných textů.
- Návrh aplikace pro management Kooperačního systému článkové bibliografie (MNG KOSABI).
- Standardizace týkající se popisu článků v UNIMARCu a implementaci standardu Dublin Core, SICI do plných textů.
- Nastínění nových metod zejména ve věcném popisu (aplikace kategorií v popisu článků a témat při zpracování i vyhledávání informací o článcích.
- Průběžné doplňování báze ANL bibliografickými záznamy.
- Zakoupení plných textů pro plnotextovou databázi, průběžné doplňování databáze a vytvoření předpokladů pro automatizované propojování bibliografických záznamů s plnými texty na základě dynamických a statických URL adres. Průběžné propojování záznamů s plnými texty na základě statických URL adres.
- Zabezpečení HW a SW podpory kooperačního systému.
- Právní zabezpečení projektu a kooperačního systému.
C.2 Závěr
Výsledkem řešení projektu v r. 2000 je návrh technologie linky automatizovaného získávání a zpracování informací o článcích a jejich následného zpřístupnění v rámci bibliografické souborné databáze ANL a fulltextové databáze ANL FULL založené na pojmovém vyhledávání systému TOPIC.
Aplikace umožňuje přípravu importního souboru bibliografických záznamů (s automaticky generovanou URL adresou) pro ALEPH a jiné systémy, založené na UNIMARCu a doplnění plných textů o metadata Dublin Core.
Návrh aplikace pro indexaci plných textů do fulltextové databáze ANL FULL , návrh formulářů pro vyhledávání a následné zobrazení výsledků vyhledávání umožní uživateli získat relevantní informace na základě kombinace vyhledávání pomocí metadat a pojmového vyhledávání.
Praktickým výsledkem v r. 2000 je příprava bibliografických záznamů k propojení s plnými texty v bázi ANL FULL na základě komponenty URL adresy. Takto připravená propojení se mohou realizovat klasickým propojením, tj. doplněním o dalších údaje URL adresy nebo v budoucnu v rámci metaknihovny na základě dynamicky generovaných adres na podkladě uživatelova dotazu. Výsledkem práce katalogizátorů v tomto roce je dále vytvoření hypertextových odkazů statického typu u dokumentů, které jsou propojovány klasickou cestou při zpracování záznamů na "stále" vystavené plné texty na Internetu.
Dalším cílem projektu v tomto roce je návrh řešení a realizace programové aplikace na provoz, správu a údržbu databáze článkové bibliografie, tj. aplikace pro management KOSABI. Jde o vývoj aplikace v systému ORACLE na základě řešení aplikací v rámci Souborného katalogu CASLIN. Jde o automatizaci všech činností spojených se správou Kooperačního systému článkové bibliografie. Cílem je doplnit a posílit integrovaný knihovnický systém ALEPH.
V rámci projektu v tomto roce byla zajištěna potřebná HW a SW podpora, projekt je ošetřen po stránce smluvní. Po experimentálním odzkoušení systému automatické indexace v r. 2001 bude možno zahájit poloprovoz systému.
Je evidentní, že v budoucnu bude nutné nabídnout uživateli přímý přístup k elektronické formě článku i jeho tištěnou podobu. Nutným předpokladem je propojení bibliografické článkové databáze na fond časopisů v tištěné formě, ale také ve formě elektronické.
C.3 Návrhy opatření
- Zajištění financování projektu v roce 2001 a dále zajištění souvisejícího projektu Propojení analytických záznamů s plnými texty - optimalizace zpřístupnění plných textů, který tento projekt saturuje koncepčně a doplňuje finančně. Koordinace s ostatními stávajícími i budoucími projekty v NK i jinde.
- Posílení vazeb stávajícího KOSABI na existující kooperační systémy na nižší úrovni z hlediska správního, zejména systém LANIUS.
- Personální zajištění projektu z hlediska počtu pracovníků oddělení analytického zpracování v NK. Další redukce v oddělení jsou nežádoucí (v roce 2003 bude mít oddělení 11 úvazků z původních 17 v r. 1999). Vzhledem k redukcím oddělení nebude možno v dalších letech dodržet výši finančního vkladu oddělení do projektu.
- Existence souborů autorit v oblasti jmenného a věcného popisu jsou nutným předpokladem kvalitního zpracování a vyhledávání informací. Přesunutí kapacit do příslušných oddělení tuto situaci pomohou řešit.
- Přísnější výběr článků k indexaci deníků s cílem vyloučení subjektivního faktoru při excerpci deníků.
- Funkčnost propojovacích vazeb v systému ALEPH a možnosti expanze a spolehlivosti systému v tomto ohledu. Moderních informačních systémy jsou založeny na propojování sekundárních informací s primárními jak klasickými tak elektronickými, ale také na vzájemném propojování sekundárních informací o různých typech dokumentů. Nejde pouze o propojení záznamů s plnými texty, ale také o provázání seriálů a jednotlivých čísel na analytický rozpis článků obsažených v seriálu v rámci báze NKC či Souborného katalogu CASLIN, dále pak připojení článků - recenzí k recenzovaným dokumentům v rámci těchto bází. Navigační systémy na úplné obsahy čísel seriálů mimo záběr abstraktových databází jsou v zahraničí zcela běžné.
- Praktické odzkoušení aplikací v rámci experimentu v r. 2001.
- Nutnost řešení problému autorizace uživatelů z hlediska jednotného přístupu do informačního systému NK a ošetření přístupu uživatelů do plnotextové databáze v budoucnu z hlediska autorskoprávního.
D Použití finančních prostředků
D.1 Komentář
(Souhrnná zpráva podána 15.11.2000, od té doby další čerpání prostředků).
Využití investičních prostředků. Přiděleno 1 295 000,00,- Kč. Čerpáno 1295 000,00 Kč.
Čerpáno do 15. 11. 2000: Dell Computer - 588 955,00,- Kč, Search ´97 - TOPIC - 523 979,00 Kč, PC-PIII-7000 Mhz - 77 958,00,- Kč, ORACLE 8i - 42 941,60,- Kč, ORACLE 8i - Upgrade - 2 520,00,- Kč.
Čerpáno po 15. 11. 2000: PC - 58 646,40,- Kč.
Využití neinvestičních prostředků. Přiděleno 1 025 000,00,- Kč. Čerpáno 571 941,00,- Kč. Plánováno po 15. 11. 2000 453 059,- Kč.
V rámci neinvestičních prostředků jsou odděleny placené služby, materiál, mzdy, licence.
Čerpáno do 15. 11. 2000:
Služby: 442 842 Kč,- - linka automatické indexace Anopress, plné texty Anopress, management kooperačního systému.
Materiál: 10 050 Kč,- - CDR, diskety, pásky do tiskáren
Mzdy (OON): 82 200,- Kč (bez pojištění) - příprava k propojení, propojení, stahování plných textů v rámci konzorcia.
Licence: 367 849,- Kč - Win NT 0.4
V tomto roce nebyla realizována plánovaná zahraniční stáž z důvodu pracovního vytížení řešitelského týmu a prospěšnosti investovat ušetřené prostředky do jiných typů služeb.
Prostředky z podnikových zdrojů a jiných zdrojů činí podle smlouvy mezi NK ČR a MK ČR 576 000,- Kč. Z toho 120 000,- Kč je plánováno jako vklad Anopressu v podobě jednoho přístupu k verzi TAMTAM Profesional během řešení projektu. Verze je zpřístupněna v NK od června 2000. Při měsíční ceně tohoto produktu (15 000,- Kč) je to mnohonásobné překročení vkladu.
Pracovníci oddělení mají vložit do projektu v tomto roce 456 000,- Kč.
Vzhledem k tomu, že projekt je náročný koncepčně i realizačně zároveň, je vklad hlavní řešitelky a pracovníků oddělení (rozsáhlé korektury databáze k opravě chyb, které byly částečně způsobeny dvojí existencí báze - v CDS/ISIS a ALEPH) poměrně velký. Oddělení analytického zpracování provádí korektury záznamů nejen svých, ale i záznamů spolupracujících institucí. Konečné zúčtování vkladu bude provedeno po dokončení projektu v tomto roce.
E Resumé a klíčová slova
E.1 Resumé a klíčová slova v češtině
Resumé:
Náplní projektu je optimalizace integrace a správy heterogenních dat souborné databáze
Kooperačního systému článkové bibliografie (KOSABI). Bibliografické záznamy článků,
publikovaných v českém periodickém tisku a zpracovávané spolupracujícími knihovnami,
budou postupně propojované s elektronickou podobou článku a takto prezentované na
Internetu.
Výsledkem řešení projektu v r. 2000 je návrh aplikace pro získávání a automatickou indexaci bibliografických záznamů z plných textů a následné vytvoření importního souboru záznamů pro databázi bibliografických záznamů ANL a databázi plných textů ANL FULL v NK s implementací metadat v plných textech včetně automaticky generované URL adresy. Indexace plnotextové databáze v systému TOPIC umožňuje pojmové vyhledávání informací.
Plné texty článků byly v rámci Konzorcia Anopress průběžně stahovány a připraveny k dynamickému propojení s bibliografickými záznamy v 2. pololetí tohoto roku. Plnotextová databáze byla dále průběžně doplňována články z deníků časopisů vydanými v r. 2000 a 1998. Průběžně byly staticky propojovány záznamy a plné texty z oblasti knihovnictví a práva aj. oborů.
V roce 2000 byla průběžně aktualizována souborná databáze kooperačního systému ANL a vydáván CD-ROM s Českou národní bibliografií.
Další výsledkem řešení v roce 2000 je návrh aplikace pro správu a údržbu KOSABI. Pro kooperační systém byla zakoupena kvalitní HW a SW platforma. Celý projekt byl ošetřen smluvně.
Klíčová slova:
Plné texty; TOPIC; analytická indexace; záznam; seriály; články; zpřístupnění; souborná databáze; propojování; Kooperační systém článkové bibliografie; Česká národní bibliografie; Články v českých novinách, časopisech a sbornících; vyhledávání; automatická indexace; Anopress; COSABI; ANL; ANL FULL; plnotextová databáze; pojmové vyhledávání; CD-ROM; UNIMARC; Dublin Core; metadata
Dostupný z: http://www.ikaros.cz/node/657> [48]. VOJTÁŠEK, Filip. Knihovny zaujmou pozornost médií neobvyklými událostmi. Ikaros [online]. 2000, č. 9 [cit. 2000-11-01].
Dostupný z: http://www.ikaros.cz/node/652> [49]. JONÁK, Zdeněk. Inteligence systémů zpracování textů. Ikaros [online]. 2000, č. 1 [cit. 2000-01-05].
Dostupný z: http://www.ikaros.cz/node/1134> [50]. HEIJTING, Inge. Interconnectivity and the Hybrid Library. Ikaros [online]. 1999, č. 10 [cit. 1999-11-01].
Dostupný z: http://www.ikaros.cz/node/427> [51]. SVOBODA, Martin. Elektronické publikování. Ikaros [online]. 1999, č. 3 [cit. 1999-03-01].
Dostupný z: http://www.ikaros.cz/node/314> [52]. PAPÍK, Richard. Trendy v rozvoji informačních služeb. Ikaros [online]. 1999, č. 8 [cit. 1999-09-01].
Dostupný z: http://www.ikaros.cz/node/1028> [53]. TKAČÍKOVÁ, Daniela. Když se řekne digitální knihovna... Ikaros [online]. 1999, č. 8 [cit. 1999-09-01].
Dostupný z: http://www.ikaros.cz/node/1035> [54]. HORA, Michal, RICHTER, Vít. Veřejné informační služby knihoven - nový program pro občany a knihovny. Ikaros [online]. 2000, č. 8 [cit. 2000-10-02].
Dostupný z: http://www.ikaros.cz/node/1039> [55]. KRČMÁŘOVÁ, Gabriela. Sdílená katalogizace a CASLIN. Ikaros [online]. 2000, č. 8 [cit. 2000-10-02].
Dostupný z: http://www.ikaros.cz/node/1040> [56]. JONÁK, Zdeněk. TEXTQUEST: software pro obsahovou analýzu. Ikaros [online]. 2000, č. 5 [cit. 2000-05-02].
Dostupný z: http://www.ikaros.cz/node/576> [57]. CELBOVÁ, Ludmila. Elektronické zdroje publikované v síti Internet jako součást České národní bibliografie. Ikaros [online]. 2000, č. 6 [cit. 2000-06-01].
Dostupný z: http://www.ikaros.cz/node/602> [58]. JONÁK, Zdeněk. Pojem "informace" ve světě sdíleného pojetí skutečnosti. Ikaros [online]. 2000, č. 2 [cit. 2000-02-01].
Dostupný z: http://www.ikaros.cz/node/524> [59]. JONÁK, Zdeněk. Inteligence systémů zpracování textů. Ikaros [online]. 2000, č. 1 [cit. 2000-01-05].
Dostupný z: http://www.ikaros.cz/node/1134> [50]. JONÁK, Zdeněk. Pokles důvěry ve vědu jako důsledek změny paradigmatu vědy:(Důsledky změny paradigmatu v informační vědě. Část 1). Ikaros [online]. 1999, č. 2 [cit. 1999-02-01].
Dostupný z: http://www.ikaros.cz/node/295> [60]. JONÁK, Zdeněk. Reflektuje teorie informace a komunikace dostatečně na zvýšený zájem společenských věd o semiotické a komunikační aspekty života?. Ikaros [online]. 1999, č. 3 [cit. 1999-03-01].
Dostupný z: <URL: http://ikaros.ff.cuni.cz/ikaros/1999/c03/veda2.htm> [61]. JONÁK, Zdeněk. Krize mezilidské komunikace v období komunikační a informační exploze. Ikaros [online]. 1999, č. 5 [cit. 1999-05-01].
Dostupný z: http://www.ikaros.cz/node/351> [62]. JONÁK, Zdeněk. Vztah komunikační a obsahové struktury literárního díla. Ikaros [online]. 1999, č. 6 [cit. 1999-06-01].
Dostupný z: http://www.ikaros.cz/node/369> [63]. BURGETOVÁ, Jarmila. Právní aspekty poskytování knihovních elektronických a reprografických služeb. Ikaros [online]. 1999, č. 6 [cit. 1999-06-01].
Dostupný z: http://www.ikaros.cz/node/372> [64]. POKORNÝ, Jaroslav. Elektronické časopisy a jejich vliv na infrastrukturu vědeckých znalostí. Ikaros [online]. 1999, č. 8 [cit. 1999-09-01].
Dostupný z: http://www.ikaros.cz/node/1029> [65]. UHLÍŘ, Zdeněk. "Computing in Humanities", čili: Táhneme, anebo jsme vlečeni?. Ikaros [online]. 1999, č. 11 [cit. 1999-12-01].
Dostupný z: http://www.ikaros.cz/node/448> [66]. Projects at the Royal Library in Stockholm, Sweden [online]. Stockholm : Royal Library, updated July 1, 1999 [cit. 10. dubna 2000].
Dostupný z: http://www.kb.se/ENG/projekt.htm> [67]. HAKALA, Juha. Description of the Nordic Metadata project : Cataloguing, Indexing and Retrieval of Digital Documents [online]. Helsinki (Finsko) : Helsinki University Library, [1996] [cit. 10. dubna 2000].
Dostupný z: http://linnea.helsinki.fi/meta/projplan.html> [68]. Metadata [online]. Bath (Anglie) : UKOLN, last update 16-Feb-2000 [cit. 10. dubna 2000].
Dostupný z: http://www.ukoln.ac.uk/metadata> [69]. Cobra+ : Computerised Bibliographic Record Actions [online]. Boston Spa (Velká Británie) : COBRA+, 1997 [cit. 10. dubna 2000].
Dostupný z: http://portico.bl.uk/gabriel/en/projects/cobra.html> [70]. Dublin Core Metadata Initiative [online]. Dublin (Ohio, USA) : OCLC, c2000 [cit. 10. dubna 2000].
Dostupný z: http://purl.org/dc> [71]. The Nordic Metadata projects [online]. Helsinki (Finsko) : Helsinki University, 1996, last updated 21 February 2000 [cit. 10. dubna 2000].
Dostupný z: http://www.lib.helsinki.fi/meta/index.html> [72]. KOCH, Traugott, BORELL, Mattias. Dublin Core Metadata Template [online]. Mattias.Lund (Švédsko) : Lund universitetsbibliotek, 1997, last update 1997-08-20 [cit. 10. dubna 2000].
Dostupný z: http://www.lub.lu.se/metadata/DC_creator.html> [73]. Nordic Countries URN-generator : provided by the Nordic Libraries [online]. - Lund (Švédsko) : Lund universitetsbibliotek, 1997 [cit. 10. dubna 2000].
Dostupný z: http://lub.lu.se/cgi-bin/nmum.pl> [74]. DOI, the Digital Object Identifier System [online]. - Kidlington (Oxford, Velká Británie) : International DOI Foundation, 1998, updated 4 April 2000 [cit. 10. dubna 2000].
Dostupný z: http://www.doi.org> [75]. Uniform Resource Names (urn) Charter [online]. Reston (VA, USA) : IETF, last modified 03-Jun-99 [cit. 10. dubna 2000].
Dostupný z: http://www.ietf.org/html.charters/urn-charter.html> [76]. OLSON, B. Nancy. Cataloging Internet Resources [online]. Dublin (Ohio, USA) : OCLC, c1997 [cit. 10. dubna 2000].
Dostupný z: http://www.purl.org/oclc/cataloging-internet> [77]. SICI Generator [cit. 27.listopadu 2000].
Dostupný z: http://www.ep.cs.nott.ac.uk/~sgp/sicisend.html> [78]. ANSI/NISO Z39.56-1996. Serial Item and Contribution Identifier. ANSI/NISO, 1996 [cit. 27.listopadu 2000].
Dostupný z: http://sunsite.berkeley.edu/SICI/version2.html> [79].